AI 助手的记忆边界
晨会前二十分钟,运维负责人小周被问到一个很具体的问题:昨天让 AI 助手整理过的支付回调故障背景,今天另一个同事继续排查时,为什么也被带进了回答里?
那段背景不是假的。它来自前一天的对话,也确实帮助小周少解释了很多上下文。
但问题卡在另一个地方:这到底是小周个人的排障偏好,还是团队共同认可的服务背景?
AI 助手能记住上下文,解决的是效率问题;它该把哪些上下文记给谁看,解决的是协作边界问题。
病根:记忆没有归属
运维对话里的上下文并不都是同一种资产。
有些信息只服务某个人。比如小周经常查支付回调链路,希望 AI 助手默认优先关注这套服务;他习惯先看指标再看日志,也希望回答直接给排查顺序。
有些信息才适合团队复用。比如团队约定某类告警先看最近 30 分钟指标,某个服务的背景说明已经被多次复盘确认,某套排障口径适合沉淀为协作共识。
如果两类内容混在一起,AI 助手会越来越“懂”,但团队会越来越难解释它为什么这样回答。
技术洞察:长期记忆要先分层
- 个人记忆:承接用户自己的偏好、常用系统和回答方式
- 团队记忆:承接组织内共同认可的服务背景、排障口径和协作约定
- 知识库:承接 SOP、架构说明、排障手册等稳定文档
- 会话日志:保留一次对话的过程、引用和上下文痕迹
这几层不是为了概念好看,而是为了让后续回答能被解释、复盘和优化。
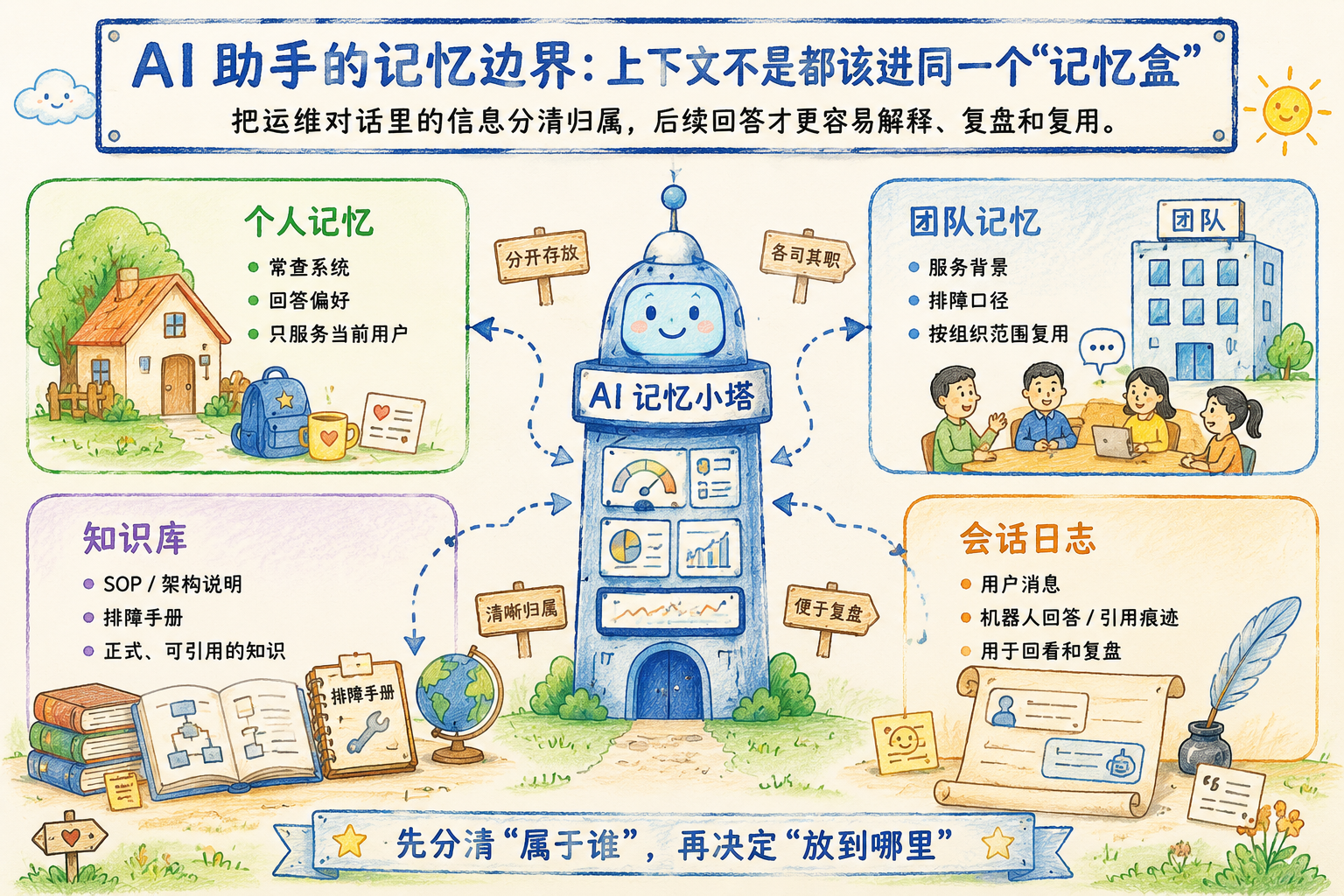
这张图要说明的是:同一段对话里出现的信息,后续归宿并不相同。把所有内容都写成长期记忆,会让知识、偏好和临时背景互相污染。
一、个人偏好
小周希望 AI 助手记住自己常查支付回调,这没问题。
但这类偏好不应该自动进入团队范围。另一个同事接手同一类问题时,可能负责的是账务集群,也可能需要先看日志分组而不是指标趋势。把小周的习惯变成团队默认,会让 AI 助手看起来更主动,实际上却把协作口径带偏。
在 BK Lite OpsPilot 中,记忆空间可以设置可见范围。个人记忆按用户隔离,更适合保存个人偏好、常用系统和回答方式。
这一层补的是个人效率,但边界必须停在个人范围内。
二、团队共识
晨会追问真正暴露的问题,是“哪些内容可以被团队共享”。
服务背景、排障口径、协作约定,如果已经被团队认可,就不应该只留在某个人的对话里。否则每次换人接手,都要重新解释一遍。
OpsPilot 的团队记忆按组织隔离,适合保存这类可以被团队共同复用的长期上下文。它让团队经验不再只沉在某个人和 AI 助手的对话中。
但团队记忆也不能变成大杂烩。临时绕行方案、尚未确认的故障猜测、一次性排障命令,都不应该因为当前有用就长期沉淀。
三、写入规则
到这里,小周已经知道记忆要分个人和团队,但还有一个更早的卡点:什么内容会被写进去?
运维现场里,很多信息只适合当前对话。
比如当天的变更窗口、某次排障里的临时判断、还没有复盘确认的影响范围。这些内容对当下有帮助,却不一定适合长期保留。
OpsPilot 的记忆空间支持写入规则,用来控制哪些信息会被自动沉淀。这样,“AI 要不要记住这件事”不再是随意发生的动作,而是进入可治理的配置边界。
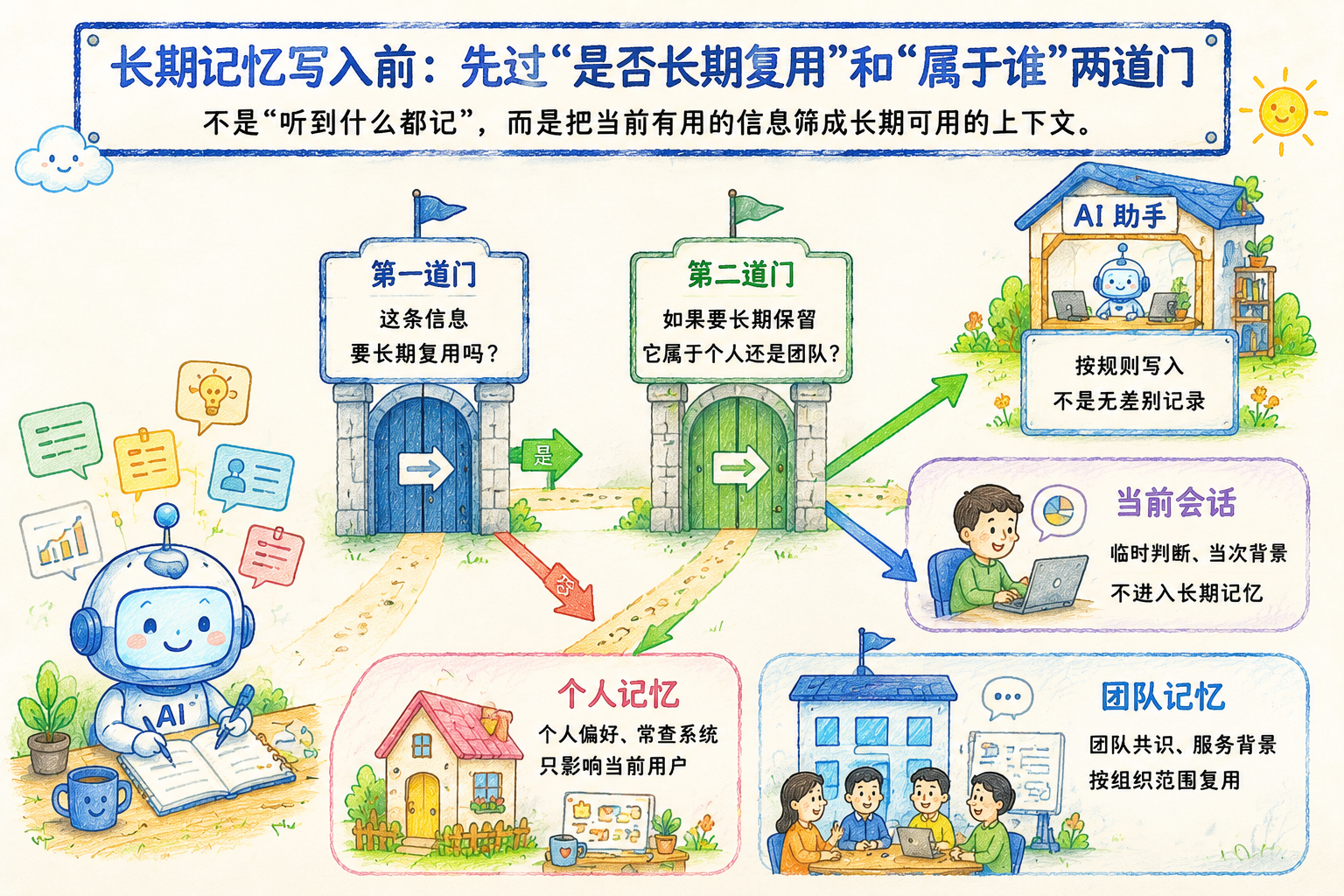
这条链路的价值在于:它把“记住”拆成几个可检查的判断,而不是把所有上下文一股脑塞进长期记忆。
四、存储边界
记忆一旦长期存在,还会涉及后端承载方式。
OpsPilot 的记忆空间可以选择存储引擎。默认可使用本地存储,也支持 Mem0、Zep 和自定义 API。不同引擎通过统一的读取、写入、删除和连接测试接口接入。
本地存储会以标题和内容形式落库,按更新时间提供最近上下文,并支持基于模型的智能合并写入。引擎配置中的敏感项会加密存储,对外返回时脱敏展示。
这里要注意一个边界:加密和脱敏解决的是配置安全,不等于自动判断业务内容是否敏感。真正决定哪些内容能进入长期记忆的,仍然是前面的可见范围和写入规则。
五、知识与日志
小周最后还需要分清另一件事:不是所有上下文都应该进入记忆。
OpsPilot 的智能体可以绑定一个或多个知识库,按知识库设置相关性分数阈值,并在回答中展示知识来源。机器人侧也支持查看会话日志,包括用户消息、机器人消息和知识引用。
这让 AI 助手的上下文来源更清楚:
| 上下文来源 | 更适合放什么 | 主要价值 |
|---|---|---|
| 个人记忆 | 偏好、常用系统、回答方式 | 提升个人连续性 |
| 团队记忆 | 团队认可的背景与口径 | 支撑协作复用 |
| 知识库 | SOP、架构说明、排障手册 | 提供可引用知识 |
| 会话日志 | 用户消息、机器人消息、知识引用 | 支撑回看和复盘 |
这样拆开以后,团队再追问“AI 为什么这么回答”时,不必只面对一个模糊的黑箱。
上手前先问几句
在给 AI 运维助手开启长期记忆前,可以先问几句:
- 这段信息是个人偏好,还是团队共识?
- 这段背景是临时判断,还是长期可复用经验?
- 它应该进入记忆,还是应该进入知识库?
- 以后复盘时,团队能不能解释它为什么被写入?
- 如果换一个人提问,这段上下文还应该继续生效吗?
这些问题看起来比“能不能记住”麻烦,但它们决定了 AI 助手能不能真正进入团队协作。
记忆不是越多越好。
没有范围的记忆,会让回答变得难解释;没有写入规则的记忆,会把临时信息变成长期背景。
AI 助手的长期记忆,首先要补上的不是容量,而是边界。