快速入门
通过本快速入门,您可以在 30 分钟内完成 BlueKing Lite CMDB 的首条落地闭环:定义资产模型、录入或导入实例、建立关系、通过视图与搜索验证结果,再用自动发现持续补齐数据。整个过程不依赖二次开发,适合团队先建立一套「可用、可查、可持续更新」的资产底座。
一、分步操作指引
Step 1:建立首个资产模型
BlueKing Lite CMDB 采用「模型驱动」设计,首先需要定义资产标准。
1.1 创建模型分类
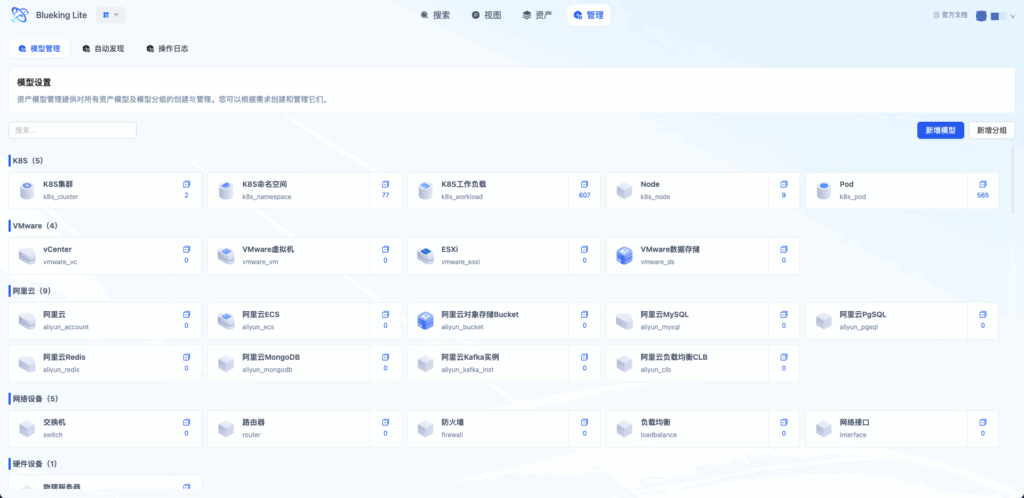
- 进入 资产模型管理 页面
- 点击「+分类」按钮,创建第一个分类
- 填写分类名称(如「主机资源」「容器平台」)
1.2 创建资产模型
- 在目标分类下点击「+模型」
- 配置模型基本信息:
- 模型 ID:英文字符,如
linux_host - 模型名称:中文显示名,如「Linux 主机」
- 图标:选择符合资产类型的图标
- 模型 ID:英文字符,如
1.3 配置模型属性
进入模型详情页,在「属性」标签页配置字段:
| 推荐字段 | 字段类型 | 约束建议 | 用途说明 |
|---|---|---|---|
ip_addr | 字符串 | 必填、唯一 | 主标识,用于关联和搜索 |
status | 枚举 | 必填 | 运行状态,引用公共选项库 |
environment | 枚举 | 必填 | 环境类型(生产/测试/开发) |
owner | 用户 | 可编辑 | 资产负责人 |
tags | 标签 | - | 灵活打标,支持多维度检索 |
1.4 设置字段分组(可选)
- 切换到「字段分组」标签页
- 创建「基础信息」「网络配置」「运维信息」等分组
- 拖拽字段到对应分组,调整展示顺序
1.5 定义模型关系
- 切换到「关联」标签页
- 点击「+添加关联」,配置关系类型:
- 源模型:当前模型
- 目标模型:相关联的模型(如「业务系统」「网络设备」)
- 关系类型:选择「运行于」「依赖于」「包含」等
- 映射约束:设置 1:1、1:n、n:n 等
界面指引:
- 图表解读:模型管理页采用「分类-模型-详情」三级导航。左侧分类树支持拖拽排序,中间模型卡片展示实例统计,右侧详情页通过标签页组织属性、分组、关联等配置。
效率技巧
如需创建相似模型,可使用 模型复制 功能:
- 点击已有模型的「复制」按钮
- 选择复制「属性」「字段分组」「关联关系」
- 新模型继承全部配置,只需微调即可使用
Step 2:录入或导入首批实例
模型就绪后,开始录入实际资产数据。
方式 A:单条录入(适合验证阶段)
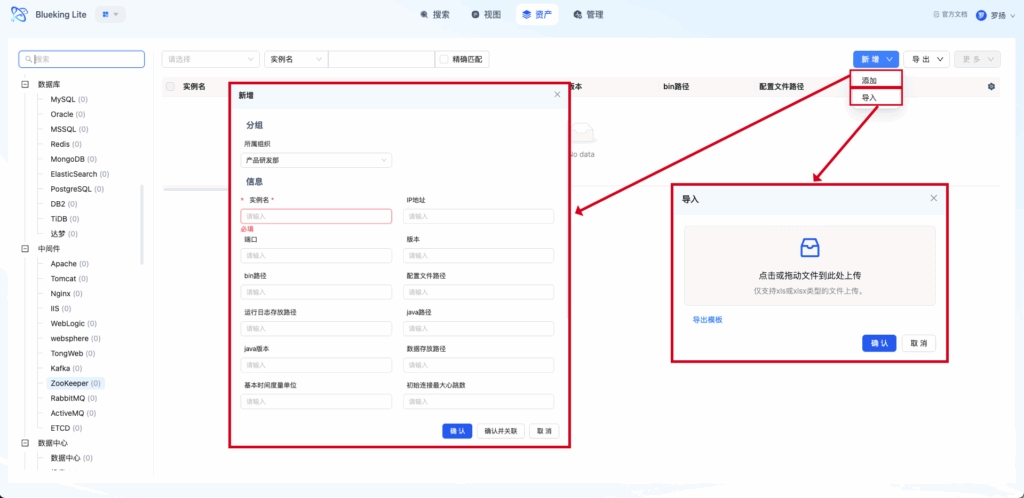
- 进入 资产数据 页面
- 选择左侧目标模型
- 点击「+新增」按钮
- 按表单填写属性值,提交保存
方式 B:批量导入(适合存量迁移)
- 在资产列表页点击「导入」按钮
- 下载导入模板(Excel 格式)
- 按模板格式整理存量数据:
- 第一行为字段名(与模型属性 ID 对应)
- 每行一条实例记录
- 枚举字段填写选项 ID
- 上传文件,系统校验通过后确认导入
导出模型配置(可勾选范围)
如需将模型定义迁移到其他环境:
- 在模型管理页右上角点击「更多 → 导出模型配置」
- 弹窗中按分类折叠树勾选需要导出的模型(默认全选)
- 点击「确认」下载
model_config.xlsx
说明:只选择部分模型导出时,已选模型所属的分类和双端都在选区内的关联关系会自动保留,跨选区的关联会被丢弃;公共枚举库始终全量导出。
注意
首次导入建议先使用 5-10 条样本数据 验证:
- 字段映射是否正确
- 唯一性约束是否冲突
- 枚举值是否匹配
验证无误后再进行大批量导入。
效率技巧
进行实例数据批量导入时,可同步规划并录入实例之间的关联关系。对于已经具备明确上下游、部署或归属关系的资产,建议在导入实例后紧接着补充关联数据,减少后续逐条建立关系的重复操作,更快形成可用的拓扑结构。
界面指引:
- 图表解读:资产列表页上方为筛选栏,支持按属性条件过滤;左侧为模型导航树;中间表格展示实例数据;右上角提供导入、导出、批量操作入口。
Step 3:建立实例关系并查看拓扑
CMDB 的核心价值在于表达资产间的依赖结构。
3.1 创建实例关联
- 在资产列表点击目标实例,进入详情页
- 切换到「关联关系」标签页
- 点击「+添加关联」
- 选择关系类型和目标实例
- 确认保存
典型关联场景示例:
| 源实例 | 关系类型 | 目标实例 | 业务含义 |
|---|---|---|---|
| MySQL 实例 | 运行于 | Linux 主机 | 数据库部署位置 |
| 业务系统 | 依赖于 | MySQL 实例 | 业务依赖关系 |
| 交换机 | 连接到 | 路由器 | 网络拓扑关系 |
3.2 查看拓扑视图
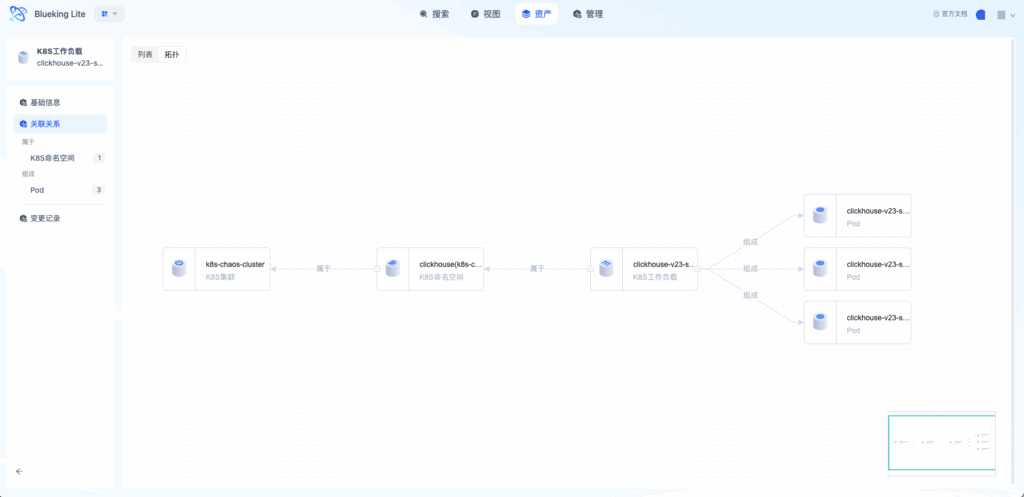
- 在实例详情页点击「拓扑视图」
- 以当前实例为中心,向上下展开关联节点
- 点击「+」扩展更多层级,点击节点查看详情
界面指引:
- 图表解读:拓扑视图采用力导向图布局,节点大小反映关联数量,连线颜色区分关系类型。支持框选、拖拽、缩放,双击节点可展开下一层关联。
3.3 专属视图(按模型自动出现)
除通用拓扑外,部分模型类型的实例详情页「关联关系」区域会自动出现专属 Tab:
| Tab 名称 | 出现条件 | 用途 |
|---|---|---|
| 网络拓扑 | 网络设备(交换机、路由器等) | 接口级网络连接图,支持多跳展开与手动连线编辑 |
| 机柜视图 | rack 模型实例 | 机柜内设备的 U 位正视图,越界/重叠高亮告警 |
| 机房视图 | server_room 模型实例 | 机房俯视平面图,按行列网格展示机柜,点击下钻到机柜视图 |
Step 4:配置自动发现任务
让 CMDB 从「一次性录入」升级为「持续同步」。
4.1 选择采集对象
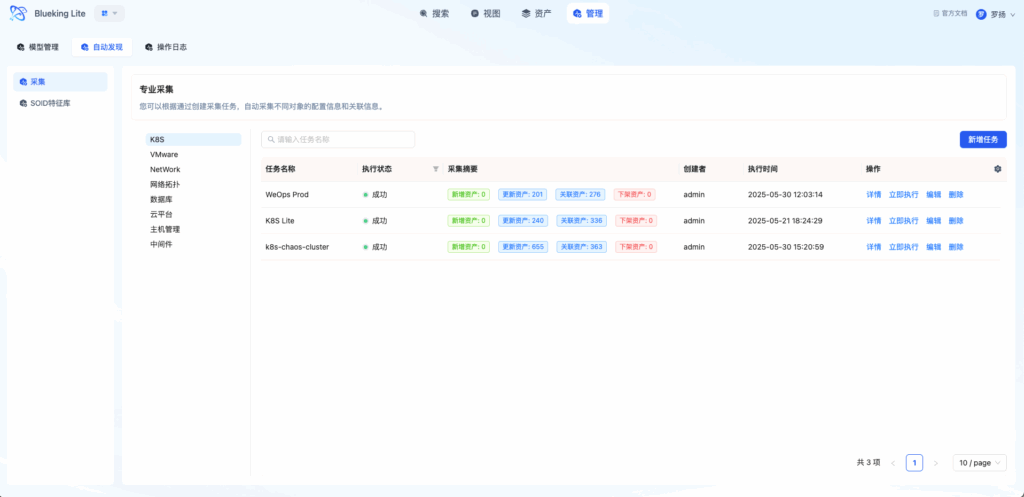
- 进入 自动发现 页面
- 在左侧「采集对象树」选择目标类型
- 支持的采集对象包括:
- 容器:K8s 集群、Docker
- 虚拟化:VMware vCenter
- 网络设备:交换机、路由器(SNMP)
- 数据库:MySQL、PostgreSQL、Redis
- 云平台:阿里云、腾讯云
- 主机:Linux/Windows 主机
- 中间件:Nginx、Kafka、Zookeeper 等
4.2 配置采集任务
点击「+新建任务」,填写配置:
| 配置项 | 说明 | 建议 |
|---|---|---|
| 任务名称 | 便于识别的名称 | 包含对象类型和环境,如「生产 K8s 采集」 |
| 驱动类型 | Protocol(协议)/ Job(脚本) | 云资源和容器选 Protocol,主机选 Job |
| 接入点 | 采集代理或网关地址 | 选择与目标网络连通的接入点 |
| 采集范围 | IP 段或实例列表 | 首次建议使用小范围测试 |
| 凭据 | 访问账号和密码 | 使用最小权限只读账号 |
| 超时时间 | 单对象采集超时 | 网络环境较差时适当调大 |
| 执行周期 | 是否周期执行 | 动态环境建议开启,如每 6 小时 |
| 录入方式 | 直接写入 / 审批后写入 | 生产环境建议选「审批后写入」 |
4.3 执行任务并查看结果
- 保存任务后,点击「执行」触发首次采集
- 等待任务完成,进入任务详情页
- 查看「采集摘要」:
- 新增:本次新发现的实例
- 更新:属性发生变化的实例
- 删除:已不存在的实例(软删除标记)
- 关联:自动发现的关联关系
- 异常:采集失败的实例及原因
界面指引:
- 图表解读:自动发现页左侧为采集对象树,不同对象图标区分类型。右侧任务列表展示执行状态,点击任务名称进入详情。详情页以卡片形式展示采集摘要,异常项可展开查看详细错误。
Step 5:验证搜索与视图功能
确认资产数据可被快速检索和浏览。
5.1 资产视图验证
- 进入 资产视图 首页
- 确认分类和模型展示正确
- 检查实例数量统计准确
- 点击模型卡片,验证可跳转至对应列表
5.2 全文检索验证
- 在顶部搜索框输入实例名称或 IP
- 查看搜索结果按模型分组的统计
- 点击实例进入详情页,验证信息完整
- 尝试切换「大小写敏感」选项,观察结果变化
界面指引:
- 图表解读:全文检索采用「模型聚合 + 实例列表」双层展示。左侧显示各模型命中数量,右侧展示具体实例。支持分页浏览,点击实例标题直接跳转详情。

Step 6:配置数据订阅
实现「数据找人」的主动通知能力。
- 进入 数据订阅 页面
- 点击「+订阅规则」
- 配置规则:
- 目标模型:选择关注的资产类型
- 筛选方式:按条件筛选或直接指定实例
- 触发条件:属性变更 / 关联变更 / 到期提醒
- 接收对象:选择通知接收人
- 通知渠道:站内信 / 企业微信 / 钉钉
- 启用规则
二、结果验证与闭环
功能验证清单
| 验证项 | 验证方法 | 预期结果 |
|---|---|---|
| 模型配置正确 | 新增一条实例,检查字段展示 | 字段分组、枚举选项、必填校验均符合设计 |
| 搜索功能正常 | 搜索 IP、名称、标签 | 秒级返回准确结果 |
| 拓扑关系准确 | 展开实例拓扑,检查关联 | 上下游依赖关系符合实际架构 |
| 自动发现生效 | 查看采集摘要 | 新增/更新数量符合预期,无异常报错 |
| 变更可追溯 | 修改实例属性,查看变更记录 | 可看到操作人、时间、前后值对比 |
三、常见问题与排查
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 导入失败 | 字段映射错误、枚举值不匹配 | 检查模板字段与模型属性 ID 是否一致,确认枚举选项 ID 正确 |
| 采集任务异常 | 网络不通、凭据错误、权限不足 | 检查接入点连通性,验证凭据有效性,确认账号权限 |
| 拓扑不显示 | 未建立模型关系、无实例关联 | 先在模型层定义关系类型,再创建实例关联 |
| 搜索结果为空 | 索引未更新、权限隔离 | 等待索引刷新(约 1 分钟),检查组织权限范围 |
| 订阅未触发 | 规则未启用、实例不匹配筛选条件 | 确认规则状态为「启用」,检查筛选条件是否包含目标实例 |
四、下一步行动
完成快速入门后,建议继续探索以下高级能力:
- 公共选项库:统一维护状态、环境等枚举值,跨模型复用
- 模型复制:快速复制标准模型到多个业务域
- 高级搜索:使用组合条件筛选,保存常用查询
- API 集成:通过 OpenAPI 将 CMDB 数据对接外部系统
- 大屏展示:基于资产数据构建可视化运维大屏
- 网络拓扑手动维护:在「网络拓扑」Tab 编辑模式中,为采集未能自动识别的链路手动补充接口直连关系
- 机房/机柜布局录入:为
rack实例录入row/col坐标,为网络设备录入rack_u_start/u_size,即可启用机房平面图与机柜 U 位视图 - 模型布局管理(管理员):以超级管理员身份进入「管理排序」模式,对分类和模型做全局排序与显示/隐藏管理
如需更多帮助,请参考「功能介绍」文档或联系平台管理员。