产品介绍
一、产品简介
BlueKing Lite 告警中心是面向轻量级运维场景打造的统一事件收敛与智能处置平台。它承接来自监控系统、日志平台、CI/CD 流水线、云厂商及第三方工具的多源事件输入,通过智能聚合引擎将分散、重复、上下文不足的原始事件转化为可分派、可协同、可审计的标准化告警与事故对象。
与传统"只发通知"的告警工具不同,BlueKing Lite 告警中心聚焦于告警从产生到关闭的完整生命周期管理。平台内置智能降噪引擎,基于多维度和多种时间窗口策略,将海量重复事件聚合成高价值的可处理单元;围绕分派、认领、转派、关闭、自动恢复、自动关闭构建标准化处置路径,确保每一条告警都能进入责任闭环;当问题升级为业务影响级故障时,支持一键升级为 事故 进行跨团队协同处置。
无论是值班运维人员的日常告警处理、团队负责人的治理策略优化,还是平台管理员的接入标准化建设,BlueKing Lite 告警中心都提供了专业、轻量且可持续演进的解决方案。
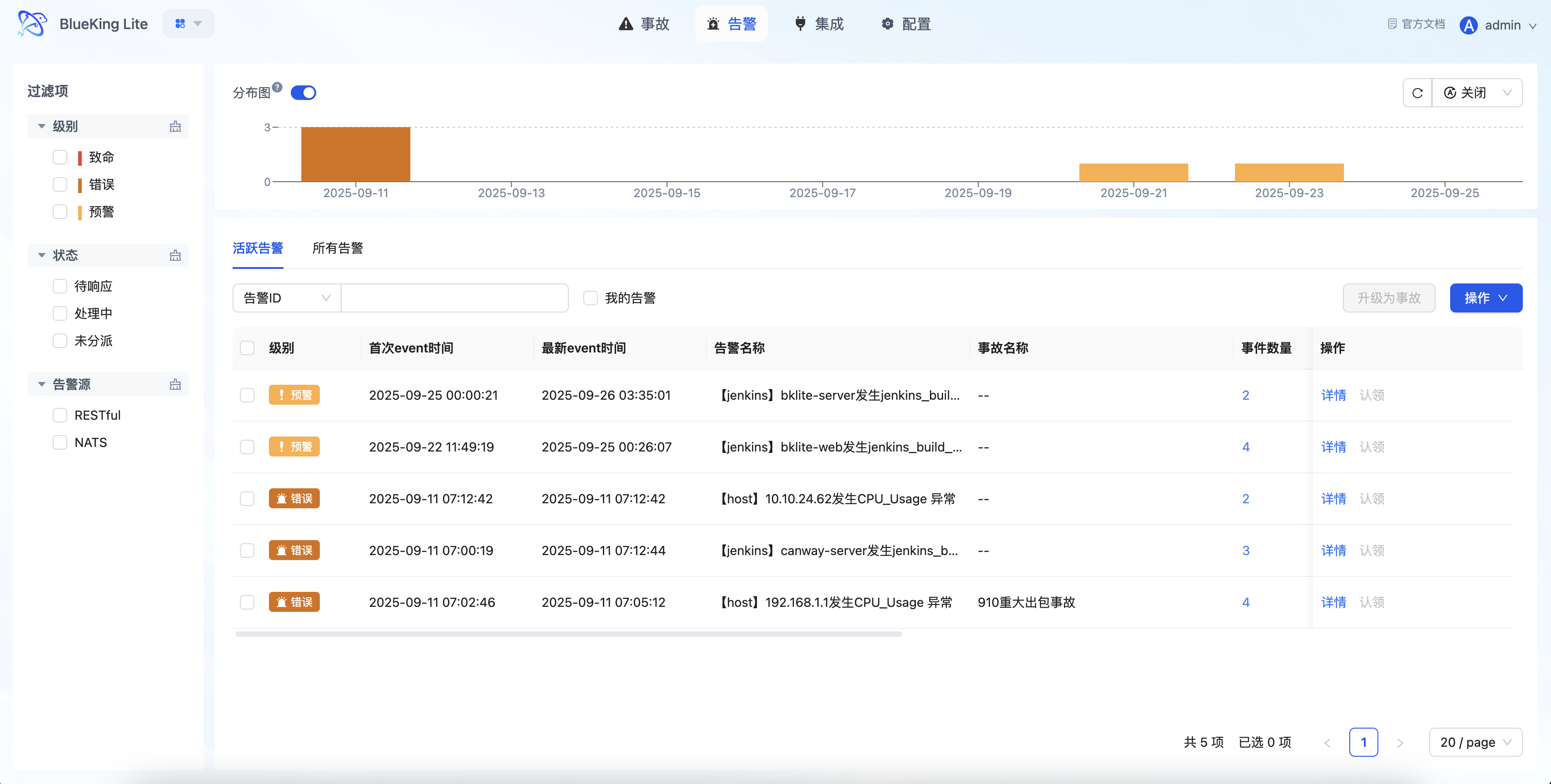
界面指引:
- 图表解读/配置逻辑:告警中心不仅是消息列表,更是统一的处置工作台。通过「级别、状态、来源、我的告警」等多维筛选,值班人员可快速定位关键问题;列表直接支持「认领、转派、关闭、升级事故」等操作,实现"发现问题 → 明确责任 → 持续跟进"的闭环处理。
二、核心优势
2.1 多源事件统一接入与标准化
平台提供 REST API 与 NATS 消息通道 双接入能力,通过可扩展的告警源适配器架构对接Prometheus、Zabbix、云监控、Webhook 等异构数据源。内置字段映射机制支持将不同来源的数据标准化为统一的事件模型,同时提供 CMDB 信息自动丰富能力,为后续聚合、分派和恢复判断奠定数据基础。
2.2 智能聚合降噪引擎
基于 DuckDB 高性能分析引擎构建的聚合处理器,支持滑动窗口、固定窗口、会话窗口三种时间窗口策略,结合多维度聚合等配置,自动计算事件指纹实现精准去重。
2.3 从通知到处置的责任闭环
平台内置完整的告警状态机(unassigned → pending → processing → resolved/closed),支持手动分派、自动分派、认领、转派等多种责任流转方式。自动分派策略支持按告警字段匹配、生效时间控制(单次/每日/每周/每月),并与通知渠道联动,确保问题第一时间触达责任人。
2.4 自动恢复与兜底关闭机制
智能关联恢复事件与历史告警,当恢复事件覆盖创建事件时自动触发 自动恢复 状态流转。同时支持基于策略的自动关闭与定时兜底任务,有效清理长期悬挂的"僵尸告警",保持告警池健康度。
2.5 会话窗口与观察期机制
针对抖动型异常场景,平台创新性地引入**会话窗口(Session Window)与观察期(Observing)**机制。告警首先进入观察期,如果在超时时间内未恢复才转为正式告警,有效过滤瞬时抖动,减少误报对值班人员的干扰。
2.6 缺失检测与心跳监控
除传统的"事件触发告警"模式外,平台支持缺失检测策略。通过 Cron 表达式配置预期心跳到达时间,当关键任务、定时作业未按时上报时自动触发告警,实现"该来的没来也知道"的守护能力。
2.7 从事故到复盘的全链路审计
告警操作、策略调整、系统设置变更全程记录操作日志;配合通知结果追踪、告警趋势统计,支持团队在事后回答"谁处理了什么问题""策略如何变更""为什么没有及时响应"等关键治理问题。
2.8 告警升级链(Escalation)
当分派告警长时间无人认领时,平台通过内置升级引擎自动推进:在每层等待时长到期后切换或扩展在岗人员集合并重新通知,升级与级内提醒独立计时、共享同一通知出口。支持**累加(append)与替换(replace)**两种升级模式,认领或关闭后自动终止升级,改派后计时从头重置,确保高影响问题不在责任交接中悬挂。
三、核心能力全景
3.1 统一的事件治理入口
BlueKing Lite 告警中心采用 Event → Alert → Incident 三层模型组织事件治理流程:
| 层级 | 定位 | 核心能力 |
|---|---|---|
| Event | 原始事件 | 多源接入、字段标准化、屏蔽过滤、恢复关联 |
| Alert | 可处理单元 | 智能聚合、状态流转、责任分派、自动恢复 |
| Incident | 事故协同 | 多告警关联、跨团队协作、升级管理 |
这种分层设计既避免了原始事件直接暴露带来的噪声问题,又为重大故障提供了清晰的升级路径。
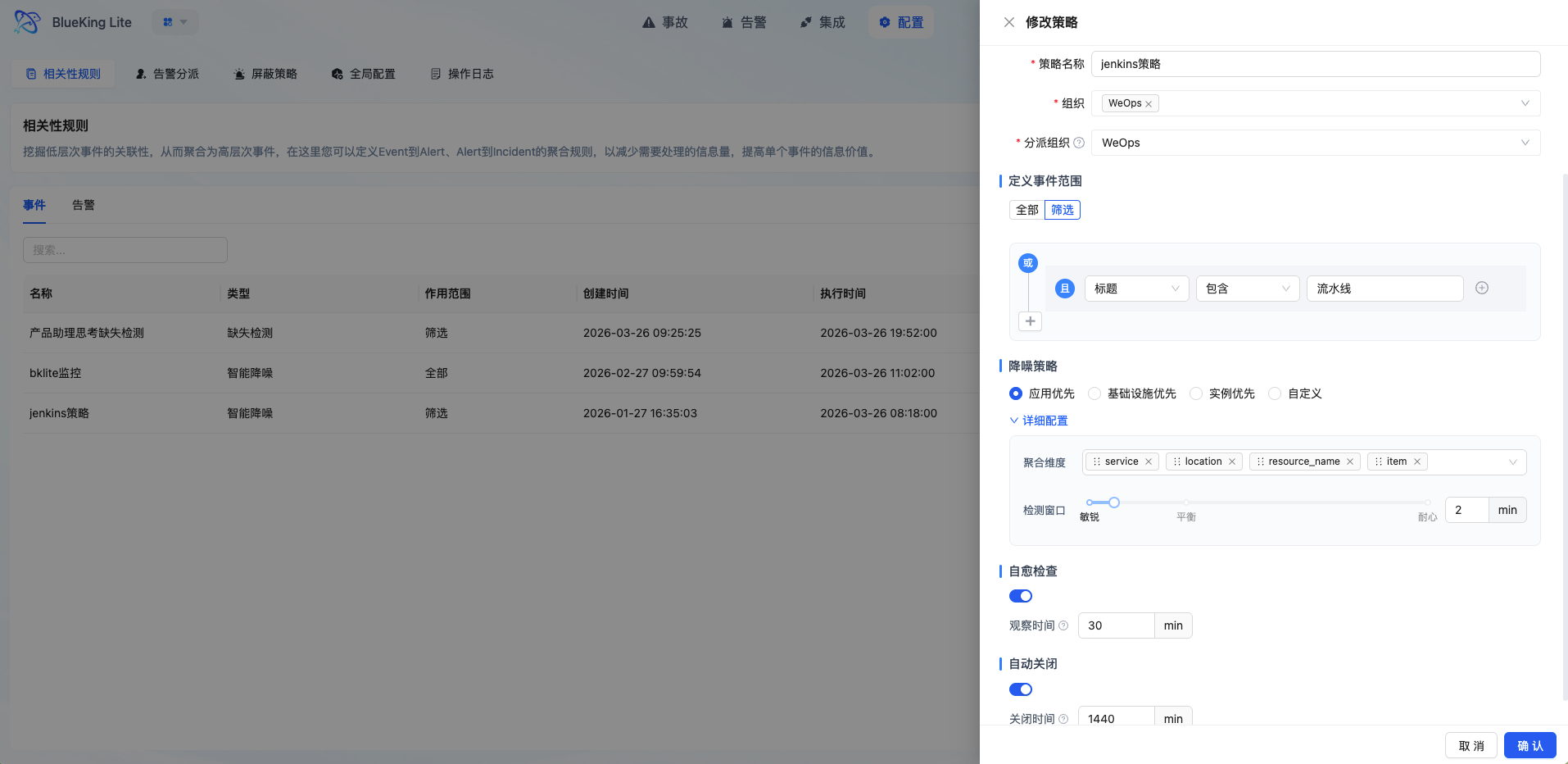
3.2 高性能聚合引擎
聚合处理器(AggregationProcessor)是告警中心的核心大脑:
- 策略驱动执行:支持智能降噪(Smart Denoise)、缺失检测(Missing Detection)、即时告警(Instant)三种策略类型
- DuckDB 内存计算:事件批量加载至内存进行聚合分析,大幅提升处理性能
- 并发安全保证:通过数据库行级锁与事件缓存机制,确保多进程场景下的聚合准确性
界面指引:
3.3 智能分派与通知体系
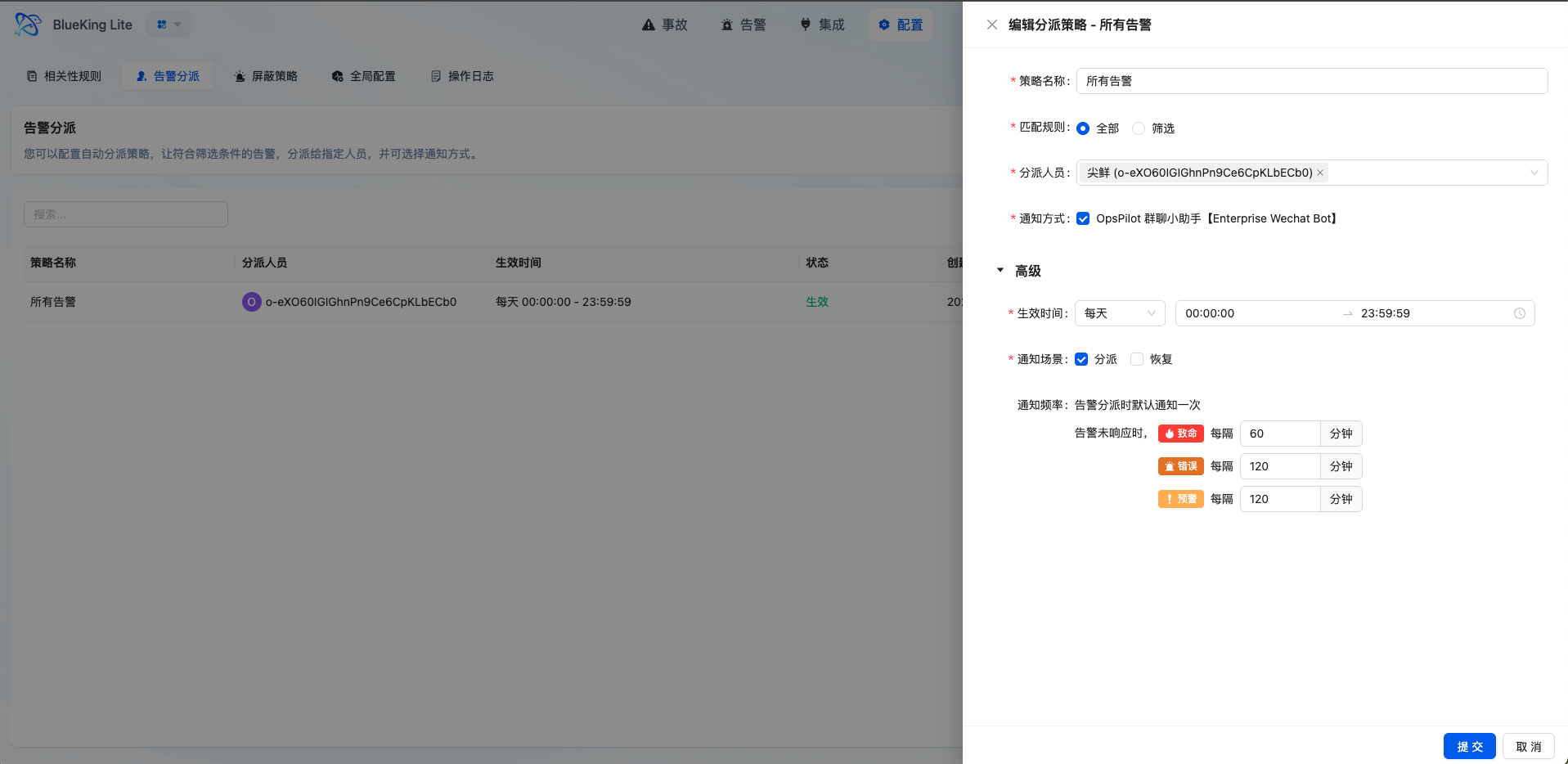
- 多级匹配策略:支持「全部匹配」与「条件过滤」两种模式,条件过滤支持多种操作符
- 灵活生效时间:支持单次、每日、每周、每月四种时间范围配置,适配不同值班排班
- 分级提醒机制:可根据告警级别配置不同的提醒频率(如致命级别每 30 分钟提醒一次,最多提醒 10 次)
- 升级链(Escalation):分派规则内可配置多层升级链,告警超时未认领时自动升级在岗人员并重新通知,支持累加/替换两种升级模式
- 兜底分派保障:未命中任何分派策略的告警进入兜底队列,按全局配置周期性通知管理员
界面指引:
- 图表解读/配置逻辑:分派策略的核心是定义"什么类型的问题在什么时间自动交给谁"。合理配置分派规则可显著减少人工判断与转派开销,提升 MTTR(平均修复时间)。
3.4 面向处理流程的告警工作台
- 多维筛选:支持按级别、状态、来源、时间范围、"我的告警"等维度快速定位
- 批量操作:支持批量分派、认领、关闭,提升高频操作效率
- 上下文追溯:告警详情页可查看关联事件列表、操作记录、通知状态,辅助判断聚合效果与处置历史
- 一键升级:高影响告警可一键升级为 Incident,进入更高等级的协同流程
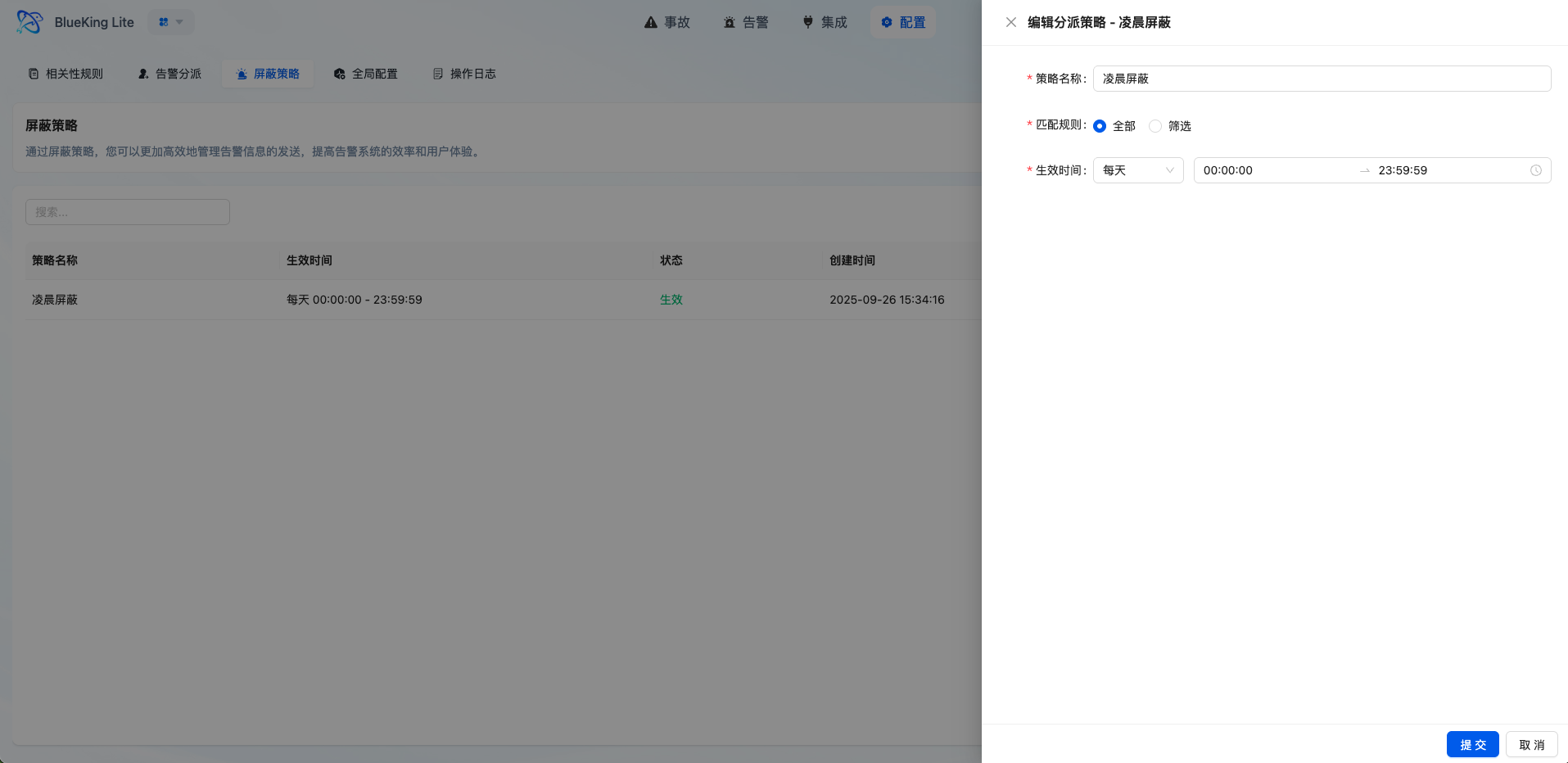
3.5 灵活的屏蔽策略
- 前置降噪:命中屏蔽策略的事件在入库后即标记为
SHIELD状态,不进入后续告警链路 - 多维度匹配:支持按来源、资源、标题、内容等字段配置匹配条件
- 时间范围控制:支持维护窗口、周期性操作等场景的临时屏蔽
界面指引:
- 图表解读/配置逻辑:屏蔽策略适合治理"明知无须处理"的事件,如计划内维护、重复性低价值通知。建议谨慎使用,避免过度屏蔽导致真正的问题被遗漏。
3.6 可观测的治理体系
- 操作日志审计:告警处置、策略变更、系统设置调整全程留痕,支持按时间、类型、操作人筛选
- 通知结果追踪:每条通知的发送结果与状态持久化存储,便于排查通知链路问题
- 趋势统计分析:支持按分钟/小时/日/周/月多粒度统计告警趋势,辅助治理决策
四、典型应用场景
4.1 基础设施异常的统一收敛
在主机、数据库、中间件等基础设施监控场景中,同一资源异常往往触发多条指标告警(CPU、内存、磁盘、连接数等)。BlueKing Lite 告警中心通过配置资源维度(resource_id、resource_type)作为 group_by 字段,将同一对象的多个指标异常聚合成单条告警,帮助运维人员识别"同一个问题"的真实影响,避免被重复事件淹没。
4.2 抖动场景的观察期过滤
网络延迟、服务瞬时过载等场景下,异常可能快速出现又自动恢复。通过配置**会话窗口(Session Window)**与观察期机制,平台将短时间内恢复的事件拦截在观察期,只有持续超时未恢复的问题才转为正式告警,显著降低误报率。
4.3 关键任务的缺失守护
对于定时备份、数据同步、报表生成等关键批处理任务,传统监控只能在任务失败时告警。通过缺失检测策略,平台可配置 Cron 表达式预期任务上报时间,当"该来的没来"时自动触发告警,守护业务连续性。
4.4 流水线失败的持续跟踪
CI/CD 流水线构建失败、镜像推送异常等事件,往往在短时间内重复触发。通过时间窗口聚合,平台将同一流水线的多次失败收敛为单条告警,便于研发团队持续跟踪问题根因而非重复接收相似通知。
4.5 重大故障的事故化协同
当告警涉及业务中断、核心链路异常或需要多角色协同处置时,值班人员可将告警升级为 Incident。Incident 支持关联多条告警、记录协同处理过程、追踪事故状态,让重大问题从"个人处理"转向"团队响应"。
4.6 合规审计与治理优化
在重视运维合规与持续改进的团队中,平台提供的操作日志、通知状态与趋势统计能力,帮助管理者回答:
- 告警响应是否及时?(分派 → 认领时长统计)
- 策略配置是否合理?(屏蔽命中率、分派成功率)
- 团队 workload 分布如何?(人均告警处理量)
五、为什么选择 BlueKing Lite 告警中心
5.1 轻量而完整的设计理念
不同于需要大规模投入的重型告警平台,BlueKing Lite 告警中心以"轻量建设、完整闭环"为核心理念。它用相对轻量的资源投入,将事件接入、聚合降噪、责任分派、自动恢复、事故升级和审计留痕串成一条完整链路,让中小团队也能快速构建企业级的告警治理能力。
5.2 技术架构的先进性
- DuckDB 内存分析引擎:聚合性能较传统数据库方案提升数倍
- 异步任务解耦:告警分派、通知发送采用 Celery 异步化,不阻塞主流程
- 并发安全设计:行级锁、指纹缓存、批量操作等机制确保高并发场景下的数据一致性
- 可扩展适配器架构:新增告警源只需实现标准 Adapter 接口,无需改动核心代码
5.3 从"能告警"到"治好告警"
BlueKing Lite 告警中心不仅关注"能不能发出一条消息",更关注告警治理体系的持续优化:
- 通过聚合降噪减少噪声,提升信噪比
- 通过自动分派缩短响应时间,提升 MTTR
- 通过自动恢复与兜底关闭保持告警池健康
- 通过审计日志支撑复盘与改进
对于希望在成本、效率与治理能力之间取得平衡的企业,BlueKing Lite 告警中心不是又一个"通知推送工具",而是一套能够持续提升运维响应质量的完整解决方案。