快速入门
一、前置条件
在开始使用告警中心前,建议先确认以下准备项已经完成:
- 已具备可访问 BlueKing Lite 平台的账号,并拥有告警中心相关模块的查看与配置权限。
- 已创建可用的告警源(路径:告警中心 → 集成 → 告警源),并获取对应的接入密钥(
SECRET)。 - 已明确需要接入的事件字段。为保证聚合、分派和恢复判断的准确性,建议每条事件至少包含:
title:事件标题(必填,缺失会导致事件被丢弃)action:事件动作(created/recovery/closed,强烈建议)level:事件级别(建议)start_time:事件开始时间(建议)resource_id/resource_name:资源标识(建议)resource_type:资源类型(建议)
- 已明确本次希望验证的场景,例如基础设施异常聚合、流水线失败跟踪或定时任务缺失检测。
注意: 告警中心的效果高度依赖事件字段质量,若缺少资源标识,聚合维度将受限,可能产生大量重复告警。
二、第一步:配置告警源与字段映射
路径:告警中心 → 集成 → 告警源 → 新建
2.1 创建告警源
- 填写告警源名称与描述
- 选择接入类型(RESTful、Prometheus、Zabbix 等)
- 配置字段映射(
event_fields_mapping):将上游系统字段映射到标准事件字段
默认字段映射示例:
{
"title": "title",
"description": "description",
"level": "level",
"start_time": "start_time",
"end_time": "end_time",
"external_id": "external_id",
"item": "item",
"resource_id": "resource_id",
"resource_name": "resource_name",
"resource_type": "resource_type",
"service": "service",
"location": "location"
}
2.2 获取接入密钥
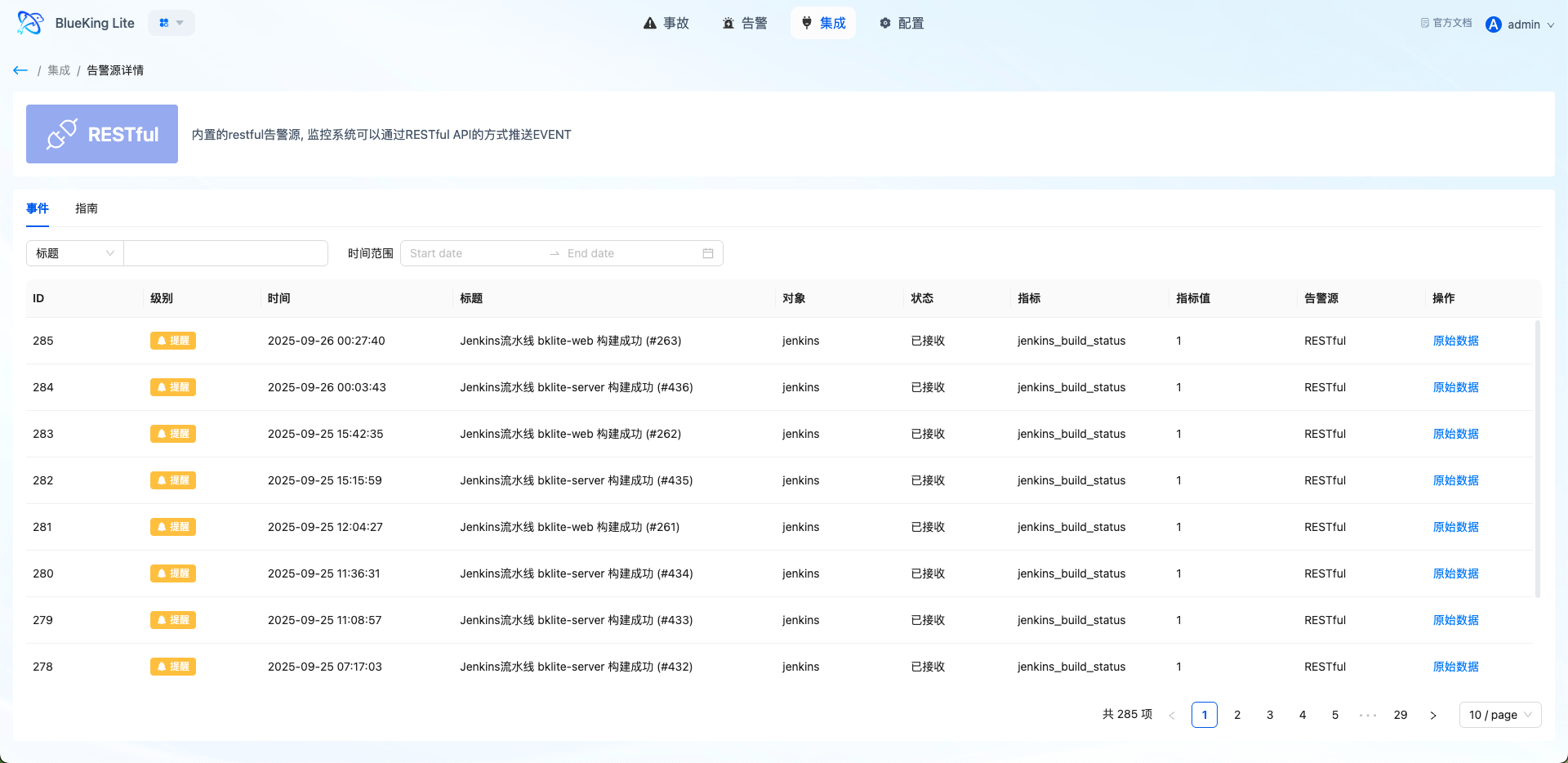
创建完成后,进入告警源详情页,复制生成的 SECRET 密钥,用于后续事件推送的鉴权。
界面指引:
- 图表解读/配置逻辑:告警源详情页展示接入指南、鉴权参数和最近事件。若接入后没有看到预期告警,应先在此确认事件是否已成功接收。
三、第二步:定义相关性规则
路径:告警中心 → 配置 → 相关性规则 → 新建
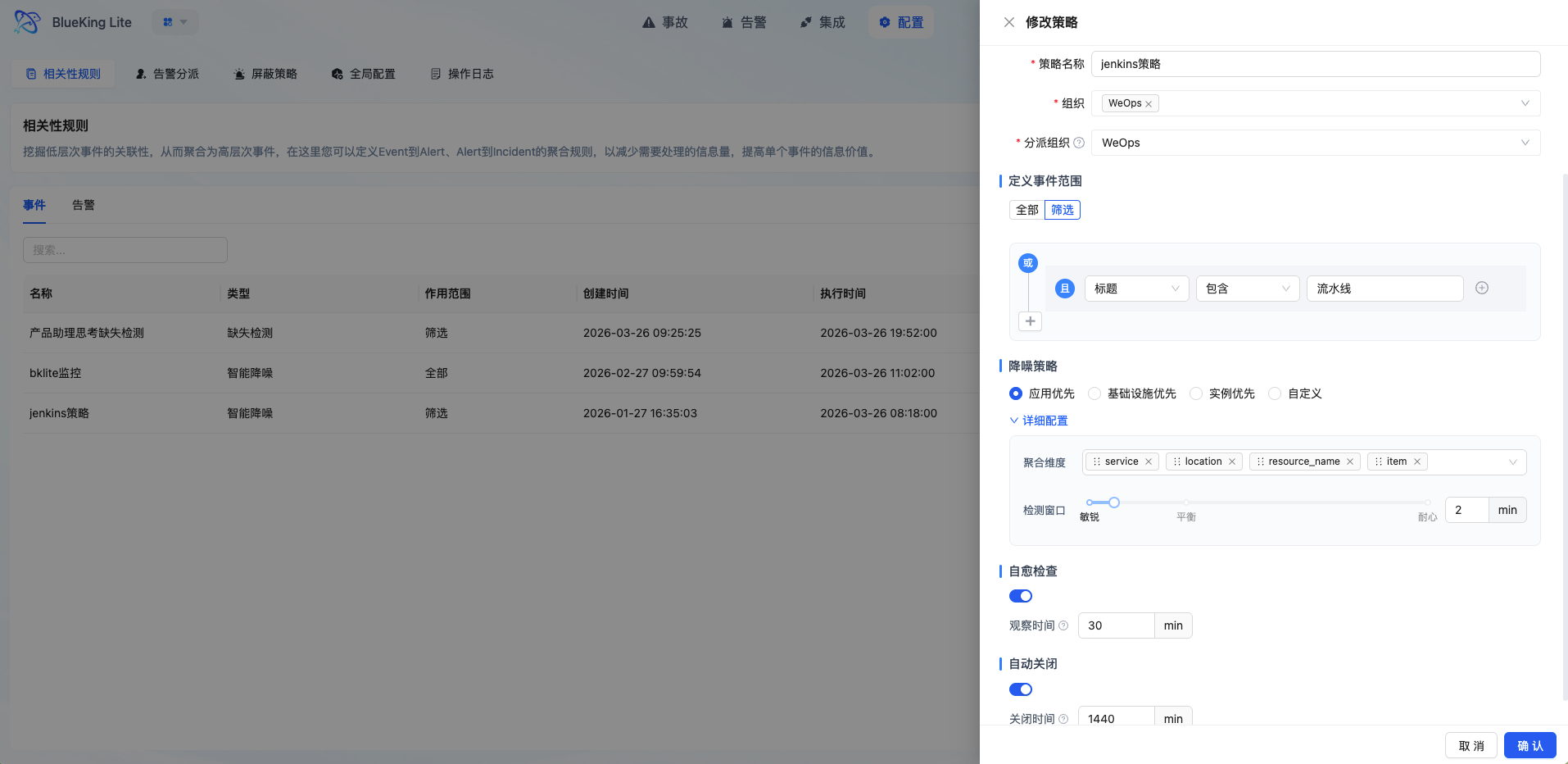
当前版本的相关性规则本质上是统一的告警策略配置入口,策略类型分为 智能降噪 与 缺失检测 两类。它决定事件进入平台后如何被筛选、聚合,以及在什么条件下生成告警。
3.1 先选择策略类型
| 策略类型 | 适用场景 | 当前核心配置 |
|---|---|---|
| 智能降噪 | 常规监控事件收敛、重复事件合并、抖动场景降噪 | 事件范围、聚合维度、检测窗口、自愈观察时间、自动关闭 |
| 缺失检测 | 定时任务、心跳上报、周期事件未按时到达 | 监听目标、Cron 检查周期、宽限期、激活方式、自动恢复、告警模板 |
| 即时告警 | 关键单点异常、需零延迟感知、不需聚合的事件 | 事件范围、告警模板(标题/级别/描述) |
建议按下面的原则选择:
- 已有事件持续上送,但希望把重复异常收敛为一条告警:选择 智能降噪。
- 预期应该定时收到某类事件,但“该来的没来”也要报警:选择 缺失检测。
无论选择哪种策略,匹配规则 都用于定义“哪些事件会进入当前策略”。其结构是“外层 OR、内层 AND”:
- 同一组中的多个条件同时满足,才命中该组。
- 任意一组命中,事件就会进入当前策略。
例如可以配置为:
- 第一组:
source_id = prometheus且resource_type = host - 第二组:
service = core-api
这样最终匹配逻辑就是:(A 且 B) 或 C。
3.2 智能降噪如何配置
智能降噪用于把重复、相近或短时间内连续出现的事件聚合成更少、更可处理的告警。当前版本不再按“滑动窗口 / 固定窗口 / 会话窗口”分别配置,而是通过以下参数组合来完成降噪:
- 定义事件范围
- 可选择对全部事件生效,或通过匹配规则只处理特定来源、级别、资源类型、服务等事件。
- 选择聚合策略
- 页面提供“应用优先 / 基础设施优先 / 实例优先 / 自定义”几种方式,本质上都是预设不同的聚合维度顺序。
- 设置聚合维度
- 当前主要围绕
service、location、resource_name、item这些字段组合聚合。 - 如果希望“同一服务下的同类异常尽量合并”,优先保留
service。 - 如果希望“按实例拆分,不同实例各自产生告警”,优先保留
resource_name。
- 设置检测窗口
- 系统会在配置的时间窗口内收集事件,再按聚合维度归并生成告警。
- 窗口越短,告警生成越及时;窗口越长,聚合效果越强。
- 按需开启自愈观察时间
- 开启后,系统会先将告警放入观察阶段;如果异常在观察时间内恢复,可减少短抖动造成的正式告警。
- 按需开启自动关闭
- 对于无需长期保留的告警,可设置自动关闭分钟数,避免告警池长期堆积。
对于大多数首次接入场景,推荐先用下面这组思路验证:
- 事件范围:先按告警源或服务做过滤,避免一开始把所有事件都纳入。
- 聚合维度:优先从
service + resource_name开始。 - 检测窗口:先用 5 分钟左右的小窗口观察效果。
- 观察时间:仅在明显存在抖动告警时再开启。
3.3 缺失检测如何配置
缺失检测不是看“事件来了没有多”,而是看“预期应该来的事件有没有按时到达”。当前实现已经切换为 Cron + 宽限期 的模式,旧版固定间隔配置已经废弃。
配置时建议按下面的顺序操作:
- 明确监听目标
- 缺失检测必须配置匹配规则,不支持“全部事件”监听。
- 通常按
service、source_id、resource_type、resource_id等字段圈定心跳或任务事件。
- 设置检查周期
- 当前仅支持 Cron 表达式。
- 例如:
0 2 * * *表示每天凌晨 2 点检查一次。
- 设置宽限期
- 当到达预期时间后,系统会再等待一段宽限时间;超过宽限期仍未收到事件,才触发缺失告警。
- 设置激活方式
- 首条心跳激活:先收到第一条符合条件的事件,再进入监控状态,适合避免策略刚创建时立刻误报。
- 立即激活:策略保存后立即开始监控,适合确定任务已在稳定运行的场景。
- 设置恢复方式与告警模板
- 可开启自动恢复。缺失告警生成后,后续一旦再次收到符合条件的事件,系统会自动恢复该告警。
- 告警模板中的标题、级别、描述为必填项,用于定义缺失告警最终展示内容。
需要注意的是,heartbeat_status、last_heartbeat_time、last_heartbeat_context 这类运行态字段由系统维护,不需要在配置阶段手工处理。
界面指引:
- 图表解读/配置逻辑:相关性规则页本质上是告警策略配置入口。保存后,规则会由后台周期聚合任务自动生效;如果聚合效果不符合预期,应优先回看匹配规则、聚合维度、检测窗口或 Cron 与宽限期配置是否合理。
四、第三步:推送事件到告警中心
4.1 创建事件推送示例
使用 REST API 推送创建事件:
curl -X POST 'https://<your-domain>/api/proxy/alerts/api/receiver_data/' \
-H 'Content-Type: application/json' \
-H 'SECRET: <your-secret-key>' \
-d '{
"source_id": "restful",
"events": [
{
"title": "主机 10.10.24.62 内存使用率过高",
"description": "主机 10.10.24.62 内存使用率持续超过阈值 90%",
"action": "created",
"external_id": "host-10.10.24.62-mem-usage",
"level": "1",
"start_time": "1742812800",
"item": "mem_usage",
"resource_id": "host-10.10.24.62",
"resource_name": "10.10.24.62",
"resource_type": "host",
"service": "core-api",
"labels": {
"cluster": "prod-beijing",
"team": "platform"
}
}
]
}'
4.2 恢复事件推送示例
当问题恢复时,推送恢复事件以触发自动恢复:
curl -X POST 'https://<your-domain>/api/proxy/alerts/api/receiver_data/' \
-H 'Content-Type: application/json' \
-H 'SECRET: <your-secret-key>' \
-d '{
"source_id": "restful",
"events": [
{
"title": "主机 10.10.24.62 内存使用率恢复正常",
"description": "主机 10.10.24.62 内存使用率已降至阈值以下",
"action": "recovery",
"external_id": "host-10.10.24.62-mem-usage",
"level": "1",
"start_time": "1742816400",
"item": "mem_usage",
"resource_id": "host-10.10.24.62",
"resource_name": "10.10.24.62",
"resource_type": "host"
}
]
}'
关键要点:
- 恢复事件的
external_id必须与创建事件保持一致action字段必须为recovery或closed- 恢复时间(
start_time)必须晚于创建事件时间,才能触发自动恢复
五、第四步:验证事件与告警
5.1 验证事件入站
路径:告警中心 → 集成 → 事件
完成推送后,先进入事件页面核验原始事件是否已成功进入平台:
- 事件是否来自预期的告警源
level、resource_name等字段是否正确解析- 时间戳是否合理(避免因时区问题导致时间异常)
5.2 验证告警生成
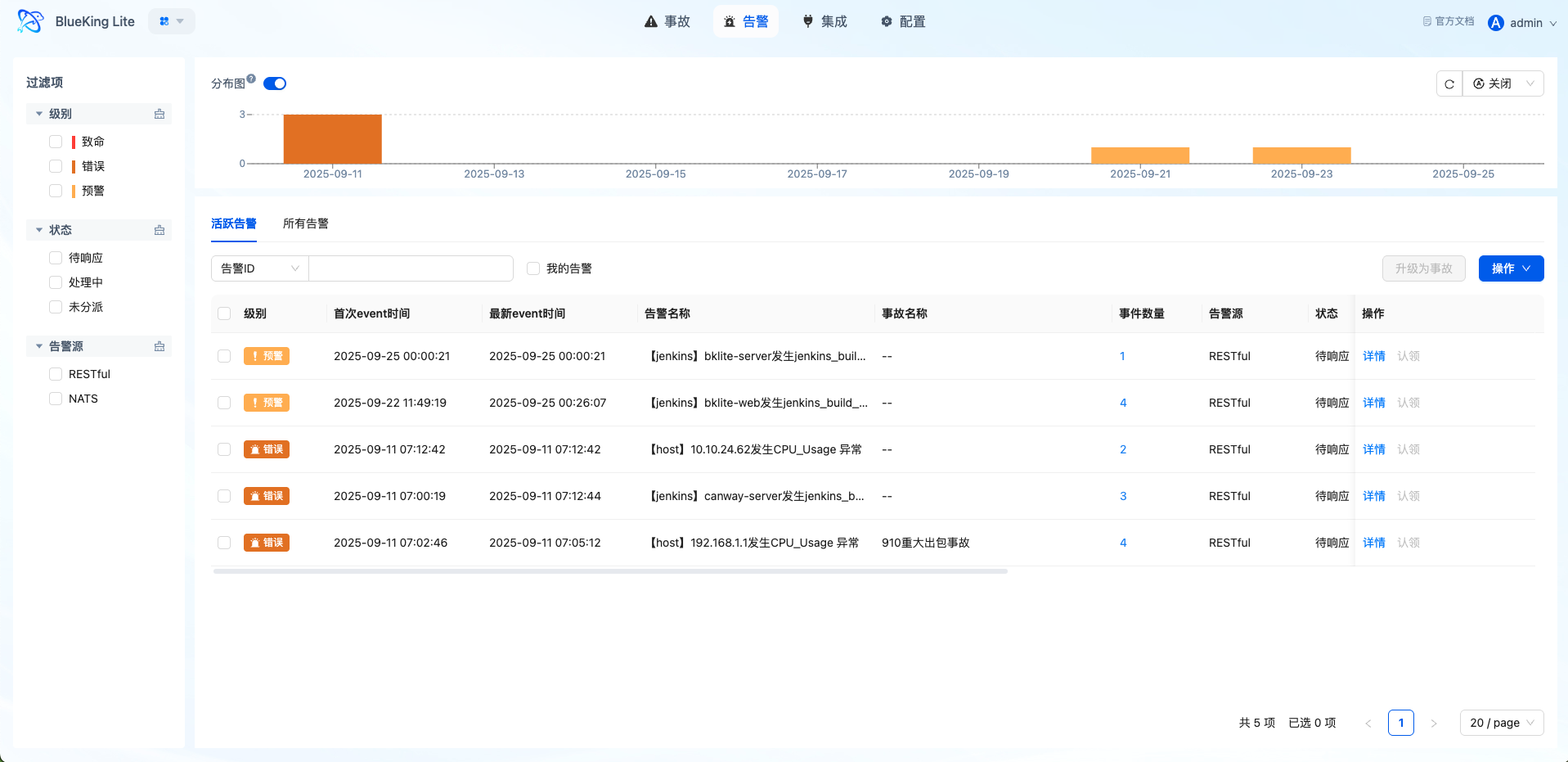
路径:告警中心 → 告警
当事件命中规则并满足窗口条件后,平台会生成对应告警:
- 告警标题、级别、来源是否符合预期
- 告警详情中是否能看到关联事件列表
- 相同
group_by维度的事件是否被正确聚合到同一告警 - 会话窗口策略的告警是否正确进入"观察中"状态
界面指引:
- 图表解读/配置逻辑:告警详情页展示关联事件、操作记录、通知状态。若发现聚合效果不符合预期,应返回检查相关性规则的分组字段与窗口配置。
六、第五步:配置自动分派策略
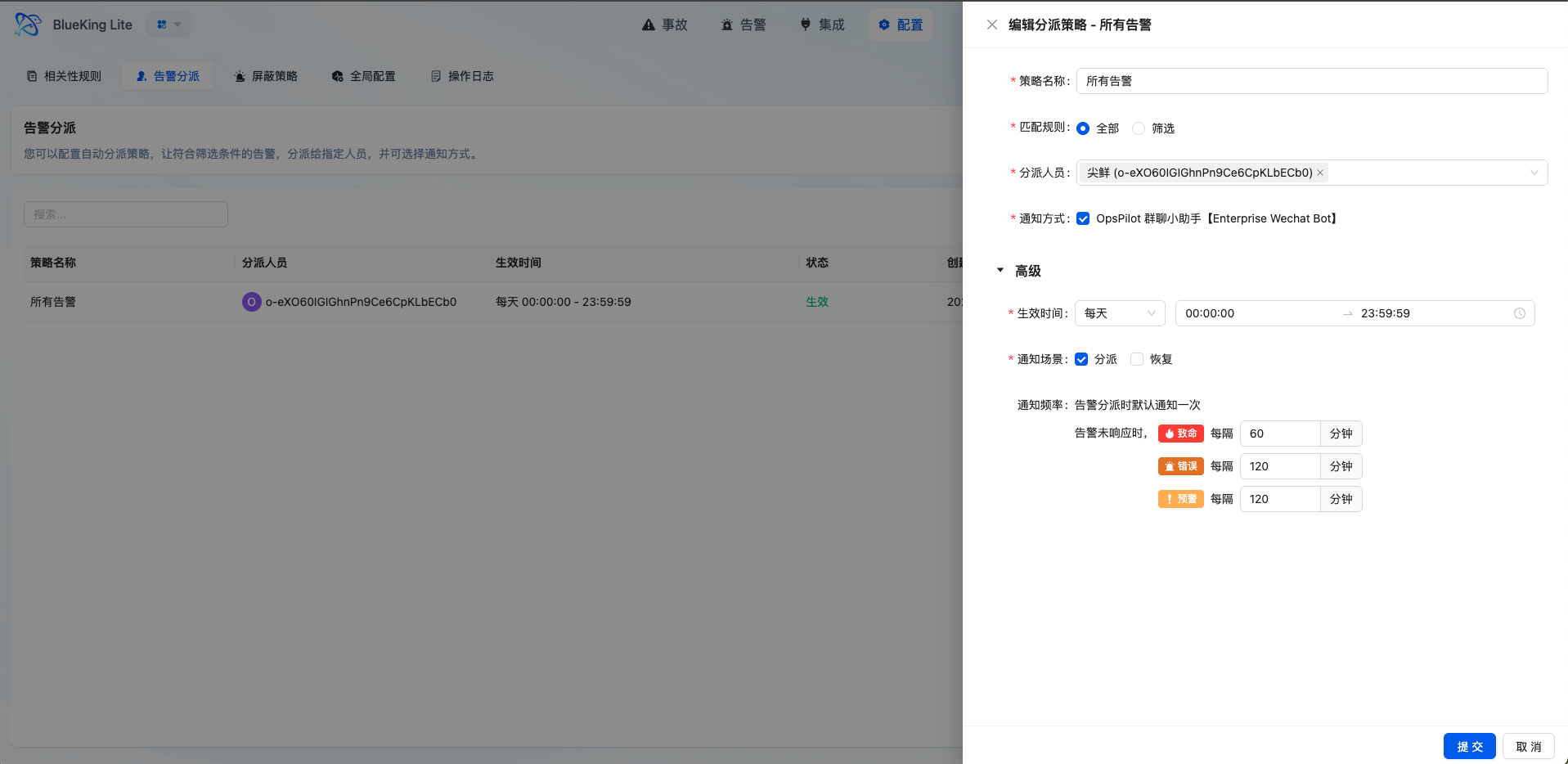
路径:告警中心 → 配置 → 告警分派 → 新建
6.1 基础配置
- 分派名称与启用状态:设置策略名称,确保「启用」开关打开
- 生效时间:选择时间范围类型(单次/每日/每周/每月)
- 匹配类型:
- 选择「全部匹配」:该时间段内所有未分派告警都会命中
- 选择「条件过滤」:配置具体的匹配规则
6.2 条件过滤配置示例
[
[
{
"key": "level",
"operator": "eq",
"value": "1"
},
{
"key": "resource_type",
"operator": "eq",
"value": "host"
}
],
[
{
"key": "source_name",
"operator": "contains",
"value": "zabbix"
}
]
]
上述规则表示:匹配(级别为致命 且 资源类型为主机)或(来源名称包含 zabbix)的告警。
6.3 分派人员与通知
- 分派人员:选择责任人(支持多选)
- 通知渠道:选择通知方式(企业微信、邮件等)
- 提醒配置:设置未响应时的提醒频率(如致命级别每 30 分钟提醒一次)
6.4 配置升级链(可选)
若希望告警在超时未认领时自动通知更高层级的负责人,可在分派策略中启用升级链:
- 开启「启用升级」开关
- 选择升级模式:累加(下层追加)或替换(下层替换)
- 逐层配置处理人与等待时长(分钟);可选配置本层专用通知渠道
示例: 第 0 层配置值班工程师、等待 10 分钟;第 1 层配置团队负责人、等待 20 分钟。若值班工程师 10 分钟内未认领,平台自动将通知升级给团队负责人。
配置完成后,新产生的告警将自动按策略分派,超时未认领则按升级链推进,减少人工判断与转派开销。
界面指引:
- 图表解读/配置逻辑:分派策略按创建时间排序,优先级由前到后。建议将更精细的匹配规则放在前面,通用的兜底规则放在后面。
七、第六步:配置缺失检测策略(可选)
对于定时任务、心跳监控等场景,可配置缺失检测策略。
7.1 策略配置步骤
路径:告警中心 → 配置 → 相关性规则 → 新建
- 策略类型:选择"缺失检测"
- 匹配规则:配置预期到达的事件特征(如
service=daily-backup) - Cron 表达式:定义预期到达的时间规律,如
0 2 * * *(每天凌晨 2 点) - 激活模式:
- 「首条心跳激活」:收到第一条匹配事件后开始监控
- 「立即激活」:策略创建后立即开始监控
- 宽限期:设置在预期时间后延迟多久未收到事件才触发告警(分钟)
- 自动恢复:勾选后,缺失告警产生后若收到匹配事件,自动恢复
7.2 工作原理
- 策略进入监控状态后,平台按 Cron 表达式计算预期到达时间
- 若预期时间 + 宽限期后仍未收到匹配事件,触发缺失告警
- 缺失告警产生后,若后续收到符合规则的事件,自动恢复该告警
注意: 缺失检测依赖 Celery 定时任务调度,请确保平台定时任务正常运行。
八、第七步:将重大问题升级为事故
当某条告警已具备明显业务影响,或需要多个角色共同处理时,可将其升级为 Incident。
8.1 升级操作
路径:告警中心 → 告警 → 选择告警 → 升级为事故
- 在告警列表选择目标告警
- 点击「升级为事故」按钮
- 填写事故标题、级别、参与人员等信息
- 确认创建
8.2 事故处理
事故创建完成后,可前往事故页面查看:
- 事故详情与状态跟踪
- 关联告警列表与处理进展
- 甘特图时间线展示事故生命周期
- 支持事故的认领、关闭、重开等操作
界面指引:
- 图表解读/配置逻辑:事故页面用于统一跟踪已升级的问题。相比告警列表,更强调协同视角与跨团队沟通。
九、结果验证与闭环建议
完成以上步骤后,建议按以下方式验证接入是否形成完整闭环:
| 验证项 | 验证位置 | 预期结果 |
|---|---|---|
| 原始事件入站 | 事件页面 | 能看到推送的事件,字段解析正确 |
| 事件聚合效果 | 告警详情 → 关联事件 | 相同维度的事件聚合到同一告警 |
| 自动分派生效 | 告警详情 → 操作记录 | 能看到自动分派记录,责任人正确 |
| 通知触达 | 告警详情 → 通知状态 | 通知发送成功 |
| 自动恢复 | 告警状态 | 推送恢复事件后,告警变为"自动恢复" |
| 升级事故 | 事故页面 | 能查看关联告警与处理进展 |
持续优化建议
- 优化聚合规则:根据实际聚合效果调整
group_by字段,避免过度聚合或聚合不足 - 完善分派策略:为高频问题场景补充更精细的分派规则,减少兜底分派比例
- 调整屏蔽策略:为维护窗口或已知低价值事件配置屏蔽策略,但避免过度屏蔽
- 优化提醒频率:根据实际处置时长调整各等级的提醒频率与最大提醒次数
- 定期复盘:结合操作日志与趋势统计,定期复盘告警治理效果