Product Introduction
1. Product Overview
BlueKing Lite Alert Center is a unified event convergence and intelligent handling platform designed for lightweight operations scenarios. It receives multi-source event inputs from monitoring systems, log platforms, CI/CD pipelines, cloud providers, and third-party tools, then transforms scattered, repetitive, and context-insufficient raw events into standardized alert and incident objects that can be dispatched, collaboratively handled, and audited through an intelligent aggregation engine.
Unlike traditional alert tools that "only send notifications," BlueKing Lite Alert Center focuses on the complete lifecycle management of alerts from creation to closure. The platform features a built-in intelligent noise reduction engine that aggregates massive duplicate events into high-value processable units based on multi-dimensional and multiple time window strategies; it builds standardized handling paths around dispatch, claim, transfer, close, auto-recovery, and auto-close, ensuring every alert enters an accountability closed loop; when issues escalate to business-impact-level failures, it supports one-click upgrade to Incidents for cross-team collaborative handling.
Whether for on-call operations personnel handling daily alerts, team leaders optimizing governance strategies, or platform administrators standardizing onboarding processes, BlueKing Lite Alert Center provides a professional, lightweight, and continuously evolving solution.
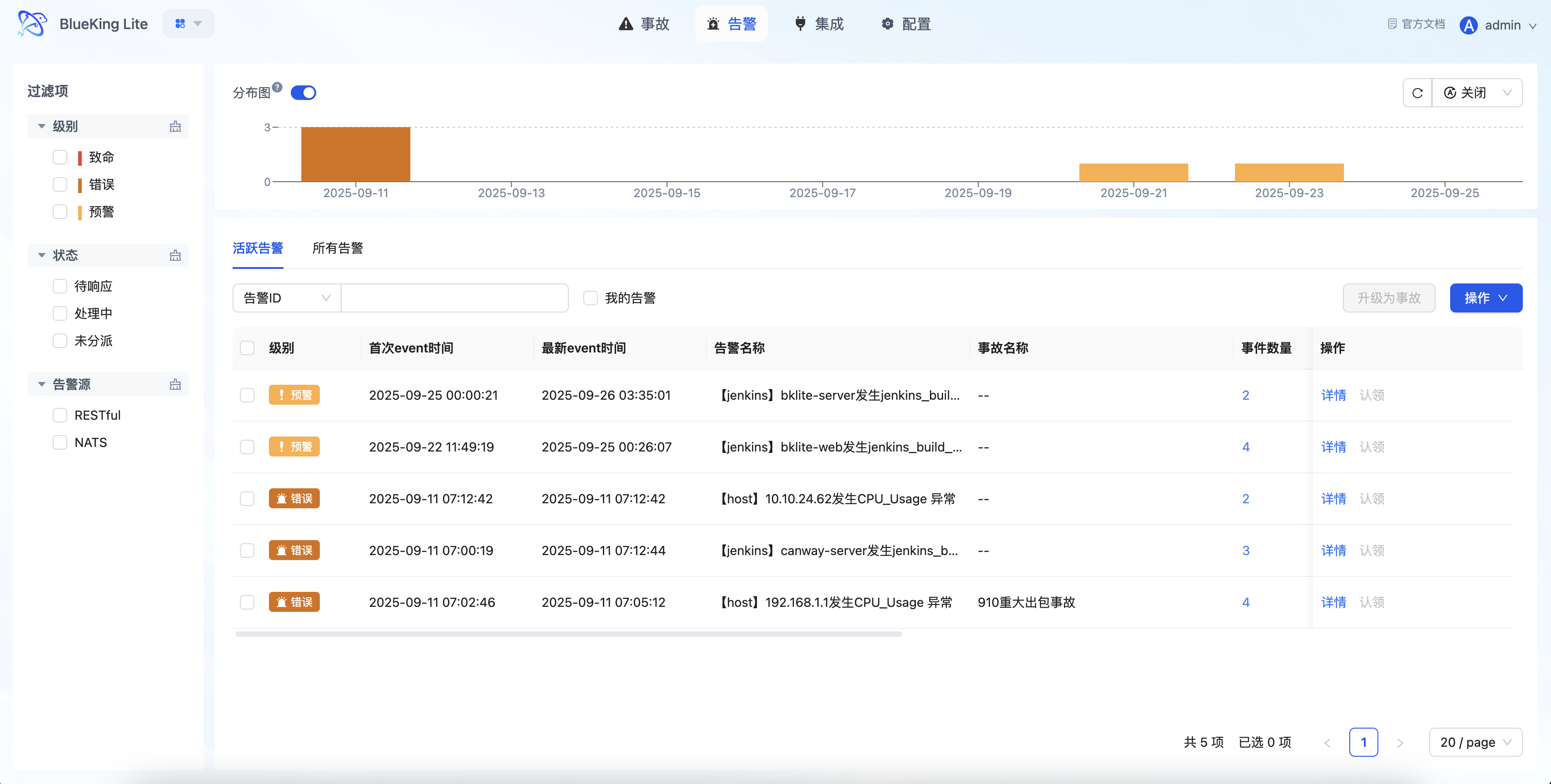
Interface Guide:
- Chart Interpretation / Configuration Logic: The Alert Center is not just a message list, but a unified handling workstation. Through multi-dimensional filtering by "Level, Status, Source, My Alerts," on-call personnel can quickly locate key issues; the list directly supports operations like "Claim, Transfer, Close, Upgrade to Incident," achieving the closed-loop flow of "discover issue -> assign responsibility -> continuous follow-up."
2. Core Advantages
2.1 Multi-Source Event Unified Onboarding and Standardization
The platform provides dual onboarding capabilities through REST API and NATS messaging channel, connecting to heterogeneous data sources like Prometheus, Zabbix, cloud monitoring, and Webhooks through an extensible alert source adapter architecture. The built-in field mapping mechanism supports standardizing data from different sources into a unified event model, while also providing CMDB information auto-enrichment capabilities, laying the data foundation for subsequent aggregation, dispatch, and recovery judgment.
2.2 Intelligent Aggregation Noise Reduction Engine
Built on the DuckDB high-performance analytics engine, the aggregation processor supports sliding window, fixed window, and session window — three time window strategies — combined with multi-dimensional aggregation configurations to automatically compute event fingerprints for precise deduplication.
2.3 Accountability Closed Loop from Notification to Handling
The platform features a complete built-in alert state machine (unassigned → pending → processing → resolved/closed), supporting manual dispatch, auto-dispatch, claim, transfer and other responsibility flow methods. Auto-dispatch policies support matching by alert fields, effective time controls (one-time/daily/weekly/monthly), and notification channel integration to ensure issues reach the responsible person at the earliest moment.
2.4 Auto-Recovery and Fallback Closure Mechanism
Intelligently associates recovery events with historical alerts; when recovery events cover creation events, it automatically triggers auto_recovery state transition. It also supports policy-based auto-close and scheduled fallback tasks to effectively clean up long-standing "zombie alerts" and maintain alert pool health.
2.5 Session Window and Observation Period Mechanism
For jitter-type anomaly scenarios, the platform innovatively introduces Session Window and Observation Period (Observing) mechanisms. Alerts first enter an observation period; only if they don't recover within the timeout period do they become formal alerts, effectively filtering transient jitter and reducing false positive interference for on-call personnel.
2.6 Missing Detection and Heartbeat Monitoring
Beyond the traditional "event-triggered alert" pattern, the platform supports missing detection policies. By configuring expected heartbeat arrival times through Cron expressions, when critical tasks or scheduled jobs fail to report on time, alerts are automatically triggered, achieving the "know when what should arrive doesn't arrive" guardian capability.
2.7 Full-Chain Audit from Incident to Post-Mortem
Alert operations, policy adjustments, and system setting changes are fully logged throughout; combined with notification result tracking and alert trend statistics, this supports teams in answering key governance questions post-incident: "who handled what issue," "how were policies changed," and "why wasn't there a timely response."
3. Core Capability Panorama
3.1 Unified Event Governance Entry
BlueKing Lite Alert Center adopts the Event -> Alert -> Incident three-layer model to organize the event governance process:
| Layer | Positioning | Core Capabilities |
|---|---|---|
| Event | Raw Event | Multi-source onboarding, field standardization, shield filtering, recovery association |
| Alert | Processable Unit | Intelligent aggregation, state transitions, responsibility dispatch, auto-recovery |
| Incident | Incident Collaboration | Multi-alert association, cross-team collaboration, escalation management |
This layered design avoids the noise problem of directly exposing raw events while providing a clear escalation path for major incidents.
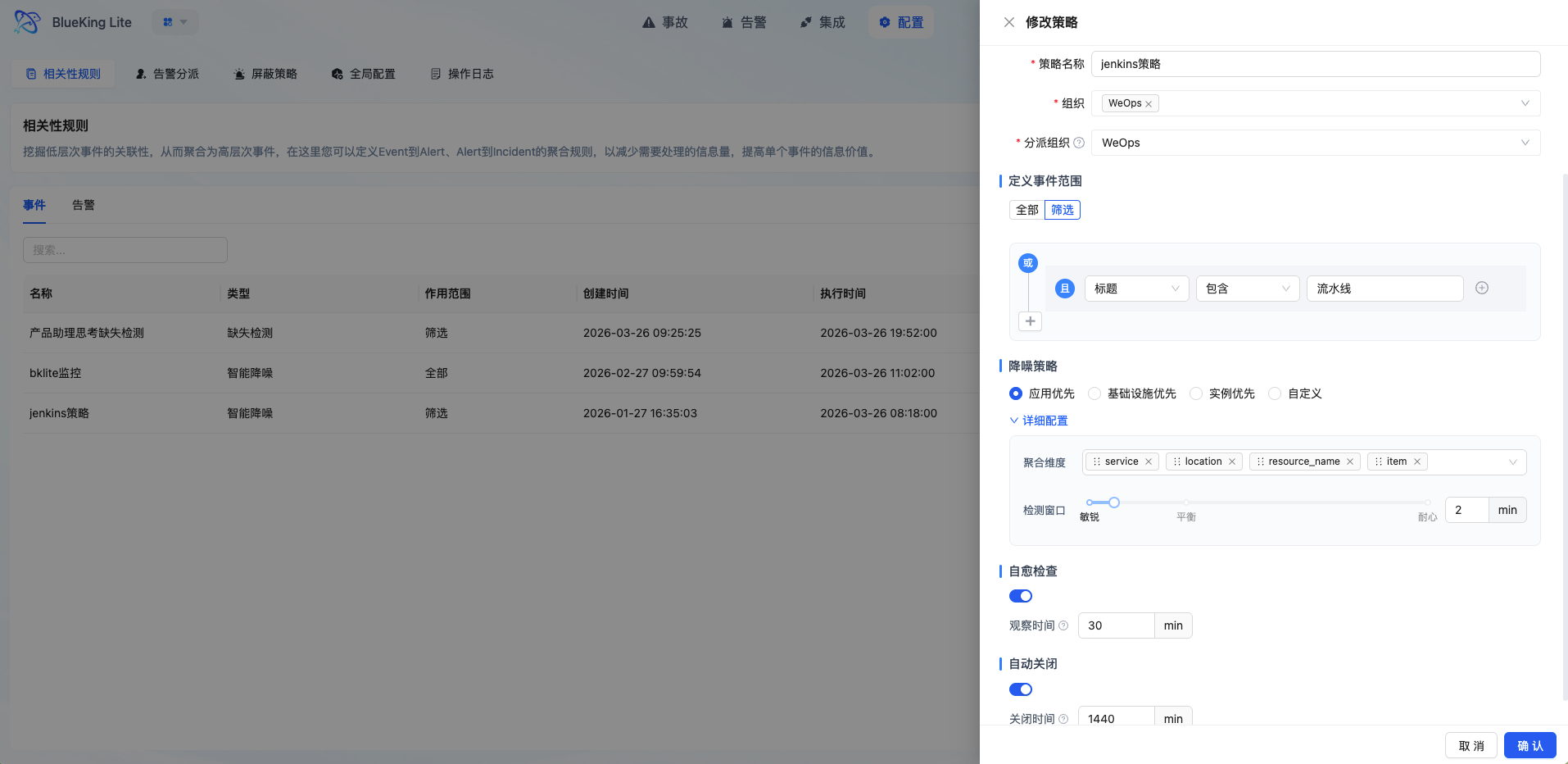
3.2 High-Performance Aggregation Engine
The Aggregation Processor is the core brain of the Alert Center:
- Policy-Driven Execution: Supports two policy types — Smart Denoise and Missing Detection
- DuckDB In-Memory Computing: Events are batch-loaded into memory for aggregation analysis, significantly improving processing performance
- Concurrency Safety Guarantee: Database row-level locks and event caching mechanisms ensure aggregation accuracy in multi-process scenarios
Interface Guide:
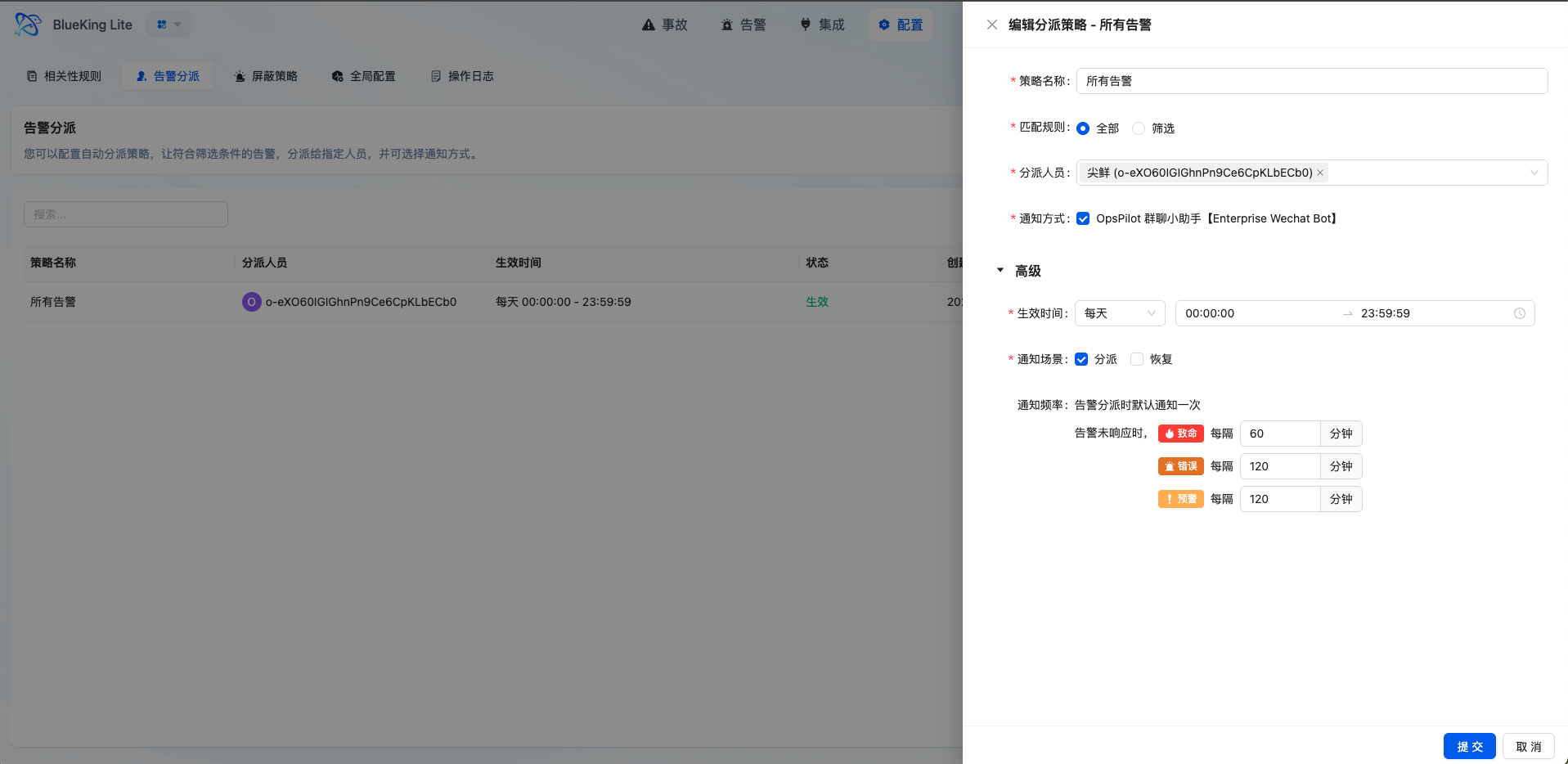
3.3 Intelligent Dispatch and Notification System
- Multi-Level Matching Policies: Supports "Match All" and "Condition Filter" modes, with condition filtering supporting multiple operators
- Flexible Effective Time: Supports one-time, daily, weekly, and monthly time range configurations to adapt to different on-call schedules
- Tiered Reminder Mechanism: Configurable reminder frequencies by alert level (e.g., fatal level reminds every 30 minutes, up to 10 times)
- Fallback Dispatch Guarantee: Alerts not matching any dispatch policy enter the fallback queue with periodic administrator notifications per global configuration
Interface Guide:
- Chart Interpretation / Configuration Logic: The core of dispatch policies is defining "what type of problem gets automatically assigned to whom at what time." Properly configured dispatch rules can significantly reduce manual judgment and transfer overhead, improving MTTR (Mean Time to Repair).
3.4 Alert Workstation Oriented Toward Handling Workflows
- Multi-Dimensional Filtering: Supports quick targeting by level, status, source, time range, "My Alerts" and other dimensions
- Batch Operations: Supports batch dispatch, claim, and close for improved high-frequency operation efficiency
- Context Tracing: Alert detail pages show associated event lists, operation records, and notification status to assist in evaluating aggregation effectiveness and handling history
- One-Click Upgrade: High-impact alerts can be upgraded to Incidents with one click, entering a higher-level collaborative workflow
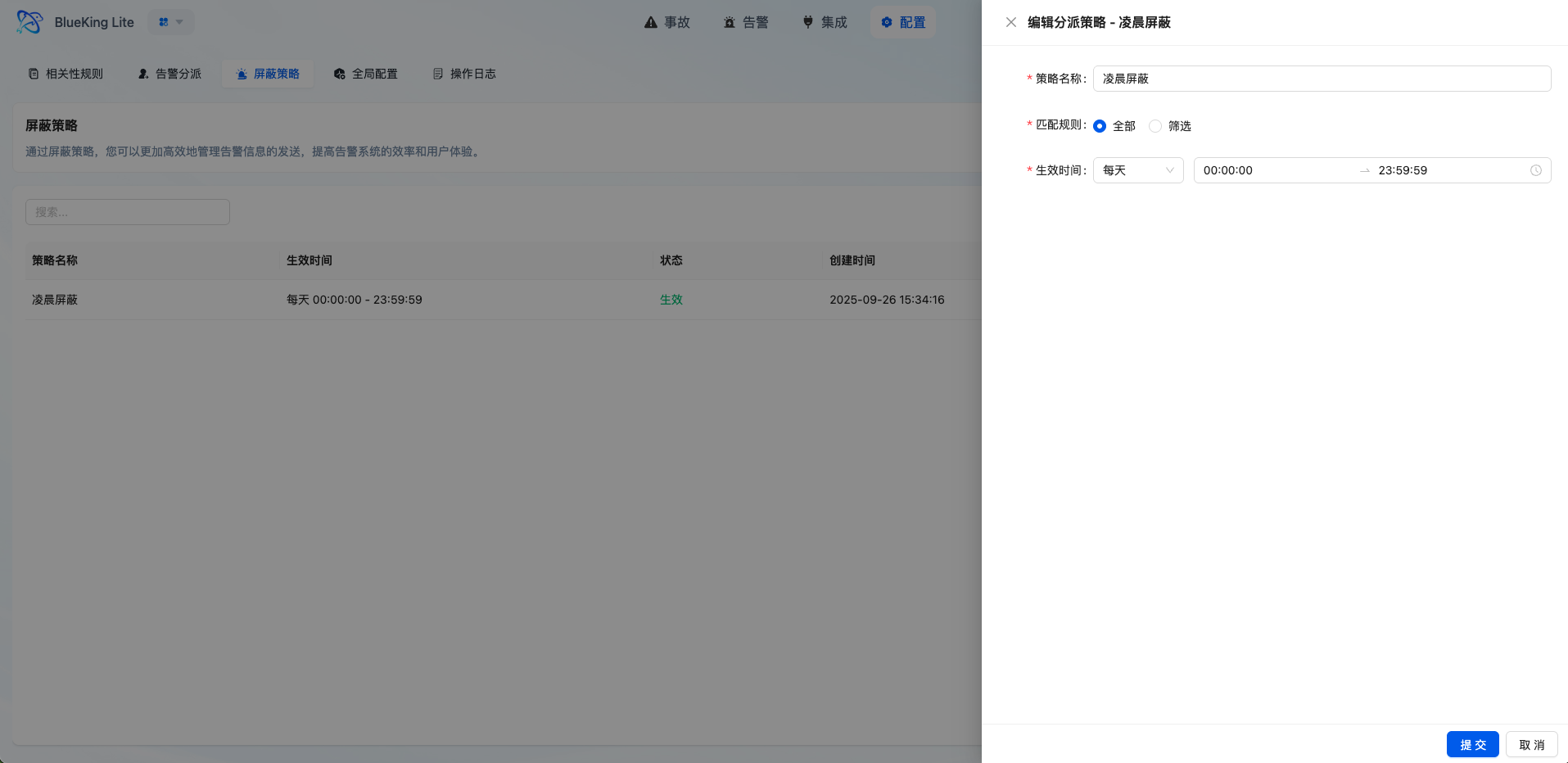
3.5 Flexible Shield Policies
- Pre-Filtering Noise Reduction: Events matching shield policies are marked as
SHIELDstatus immediately after storage, bypassing the subsequent alert pipeline - Multi-Dimensional Matching: Supports configuring match conditions by source, resource, title, content, and other fields
- Time Range Control: Supports temporary shielding for maintenance windows, periodic operations, and similar scenarios
Interface Guide:
- Chart Interpretation / Configuration Logic: Shield policies are suitable for governing "events known to not require handling," such as planned maintenance and repetitive low-value notifications. Use with caution to avoid over-shielding that causes real problems to be missed.
3.6 Observable Governance System
- Operation Log Auditing: Alert handling, policy changes, and system setting adjustments are fully tracked, with filtering by time, type, and operator
- Notification Result Tracking: Each notification's delivery result and status are persistently stored for troubleshooting notification pipeline issues
- Trend Statistical Analysis: Supports minute/hour/day/week/month multi-granularity alert trend statistics to assist governance decisions
4. Typical Use Cases
4.1 Unified Convergence for Infrastructure Anomalies
In infrastructure monitoring scenarios involving hosts, databases, and middleware, a single resource anomaly often triggers multiple metric alerts (CPU, memory, disk, connection count, etc.). BlueKing Lite Alert Center aggregates multiple metric anomalies from the same object into a single alert by configuring resource dimensions (resource_id, resource_type) as group_by fields, helping operations personnel identify the true impact of "the same problem" without being overwhelmed by duplicate events.
4.2 Observation Period Filtering for Jitter Scenarios
In scenarios like network latency and transient service overload, anomalies may appear quickly and auto-recover. By configuring Session Windows with the observation period mechanism, the platform intercepts events that recover within short timeframes during the observation period, only converting issues that persist beyond the timeout into formal alerts, significantly reducing the false positive rate.
4.3 Missing Detection for Critical Tasks
For critical batch processing tasks like scheduled backups, data synchronization, and report generation, traditional monitoring can only alert when tasks fail. Through Missing Detection Policies, the platform can configure Cron expressions for expected task reporting times, automatically triggering alerts when "what should arrive doesn't arrive," safeguarding business continuity.
4.4 Continuous Tracking of Pipeline Failures
CI/CD pipeline build failures, image push anomalies, and similar events often trigger repeatedly within short periods. Through time window aggregation, the platform converges multiple failures from the same pipeline into a single alert, enabling development teams to continuously track root causes rather than repeatedly receiving similar notifications.
4.5 Incident-Level Collaboration for Major Failures
When alerts involve business interruptions, core chain anomalies, or require multi-role collaborative handling, on-call personnel can upgrade alerts to Incidents. Incidents support associating multiple alerts, recording collaborative handling processes, and tracking incident status, transitioning major issues from "individual handling" to "team response."
4.6 Compliance Auditing and Governance Optimization
For teams that value operations compliance and continuous improvement, the platform's operation logs, notification status, and trend statistics capabilities help managers answer:
- Are alert responses timely? (Dispatch -> claim time statistics)
- Are policy configurations reasonable? (Shield hit rate, dispatch success rate)
- How is team workload distributed? (Per-person alert handling volume)
5. Why Choose BlueKing Lite Alert Center
5.1 Lightweight Yet Complete Design Philosophy
Unlike heavyweight alert platforms requiring massive investment, BlueKing Lite Alert Center is built on the core philosophy of "lightweight construction, complete closed loop." With relatively lightweight resource investment, it chains event onboarding, aggregation noise reduction, responsibility dispatch, auto-recovery, incident escalation, and audit tracking into a complete pipeline, enabling small and medium teams to quickly build enterprise-grade alert governance capabilities.
5.2 Technical Architecture Advancement
- DuckDB In-Memory Analytics Engine: Aggregation performance improved several times compared to traditional database approaches
- Asynchronous Task Decoupling: Alert dispatch and notification delivery use Celery asynchronous processing without blocking the main flow
- Concurrency-Safe Design: Row-level locks, fingerprint caching, batch operations, and other mechanisms ensure data consistency under high-concurrency scenarios
- Extensible Adapter Architecture: Adding new alert sources only requires implementing the standard Adapter interface without modifying core code
5.3 From "Can Alert" to "Governing Alerts Well"
BlueKing Lite Alert Center focuses not just on "whether it can send a notification," but on continuous optimization of the alert governance system:
- Reduce noise through aggregation to improve signal-to-noise ratio
- Shorten response time through auto-dispatch to improve MTTR
- Maintain alert pool health through auto-recovery and fallback closure
- Support post-mortem review and improvement through audit logs
For enterprises seeking balance between cost, efficiency, and governance capabilities, BlueKing Lite Alert Center is not just another "notification push tool," but a complete solution that continuously improves operations response quality.